Command Palette
Search for a command to run...
Chandra:高精度文档 OCR
一、教程简介

Chandra 是由 Datalab-to 团队于 2025 年 10 月开发的高精度文档 OCR(Optical Character Recognition)系统,专注于文档布局感知和文本抽取。 Chandra 可直接处理 PDF 和图像文件,生成结构化文本、 Markdown 和 HTML 输出,同时提供可视化布局图,便于检查 OCR 结果。
核心特性:
- 高精度 OCR:针对文档、表格和多列排版优化,支持复杂页面布局。
- 布局感知:生成可视化布局图,标记文本块、表格和图像区域。
- 多格式输出:支持 Markdown 、 HTML 、纯文本下载。
- 简单部署:基于 Streamlit 界面,可在浏览器中快速交互。
- 轻量化模型:直接使用 Transformers 加载模型,无需额外依赖 vLLM 。
本教程使用 Streamlit 部署 Chandra OCR 核心模型,算力资源采用「RTX_5090」,可快速运行文档推理与布局可视化。
二、效果展示
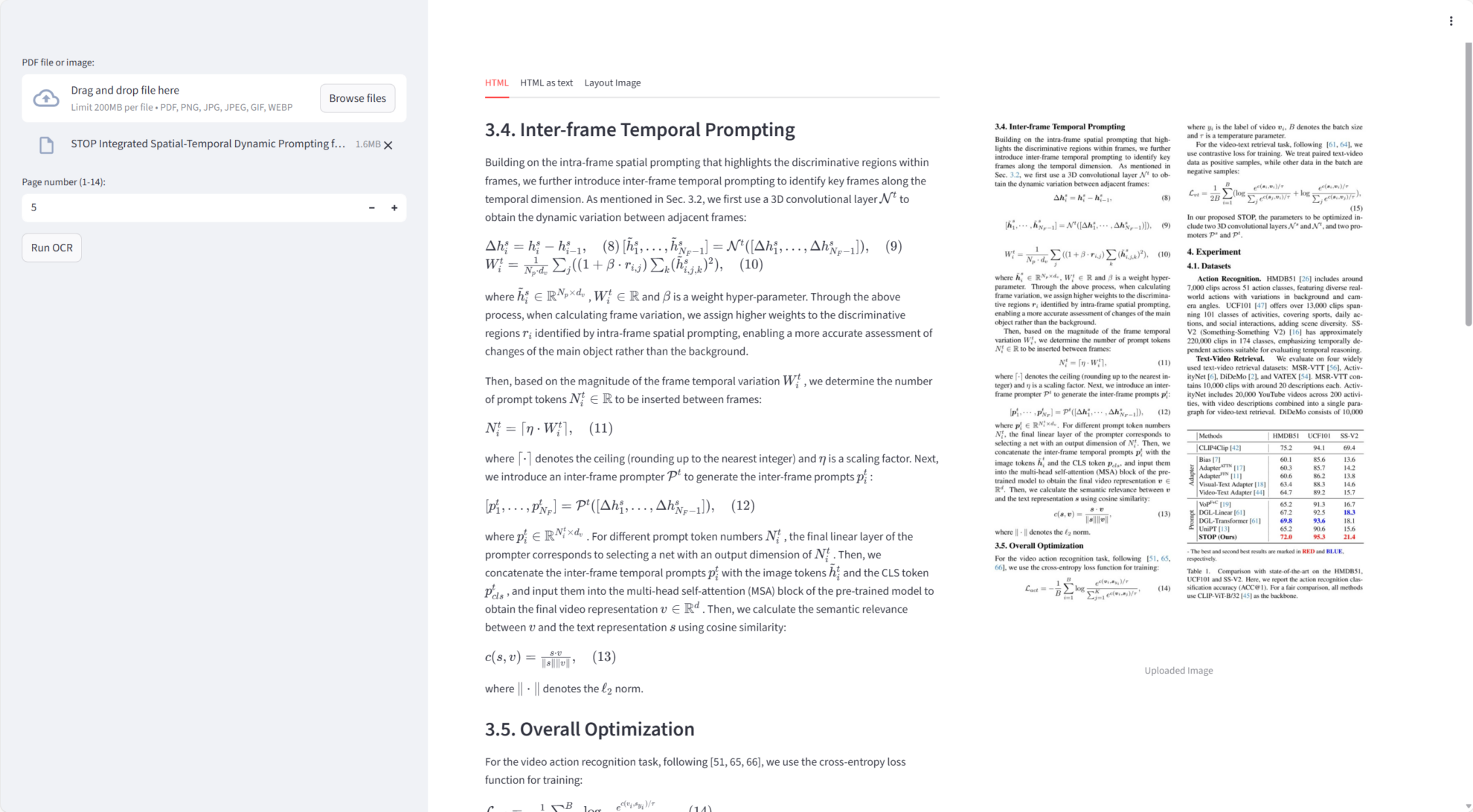
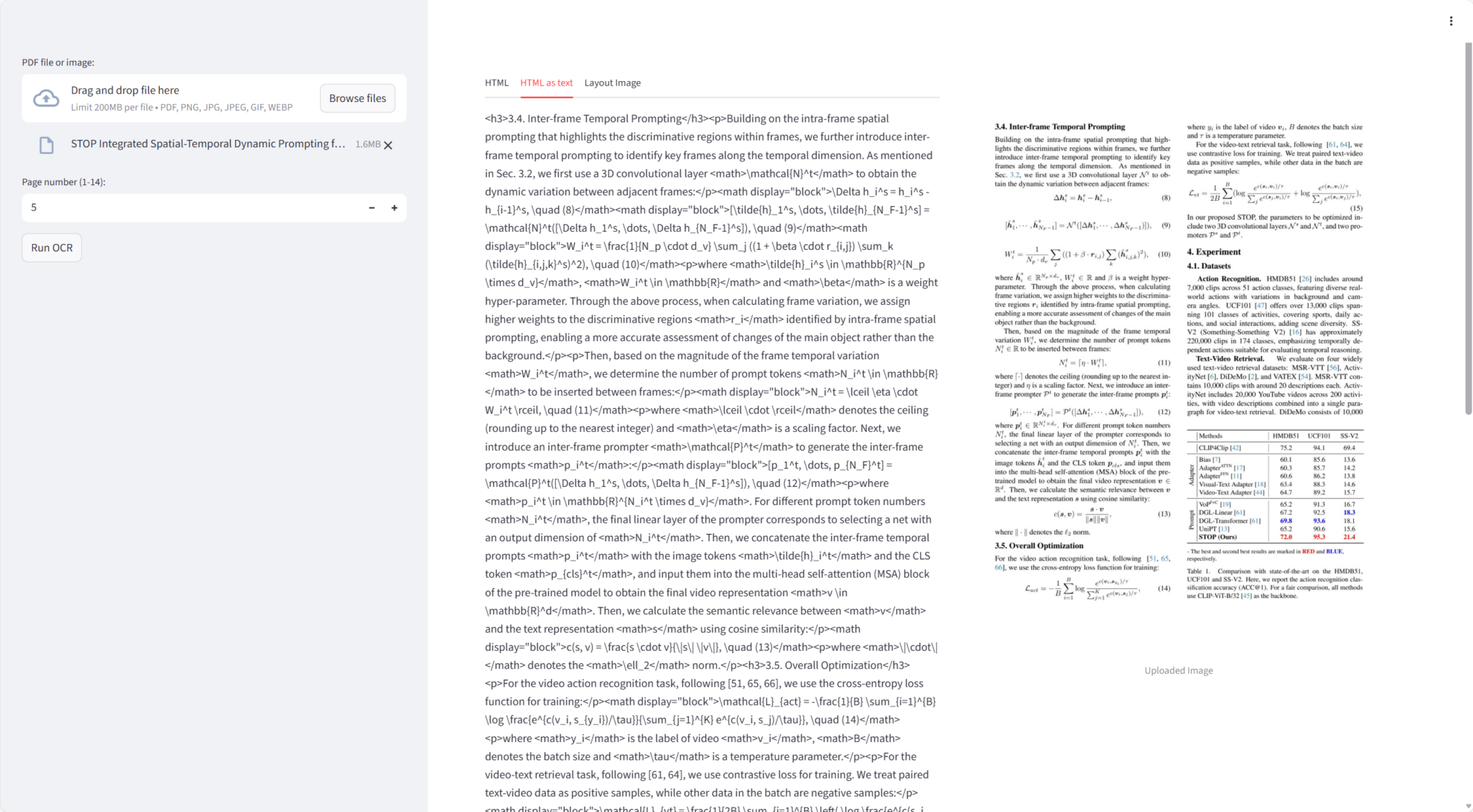

Chandra 在核心任务上表现优异:
- 单页文档 OCR:从 PDF 或图像生成高精度文本与 Markdown 。
- 布局检测:精确识别文本块、表格、图片等区域,支持布局可视化。
- 多页文档支持:可分页处理 PDF 文件,界面页码从 1 开始显示,防止越界错误。
- Markdown 与 HTML 输出:自动将 OCR 结果嵌入 Markdown 或 HTML,支持下载。
- 可视化布局图:生成标注文本区域的 PIL 图像,便于核对 OCR 精度。
三、运行步骤
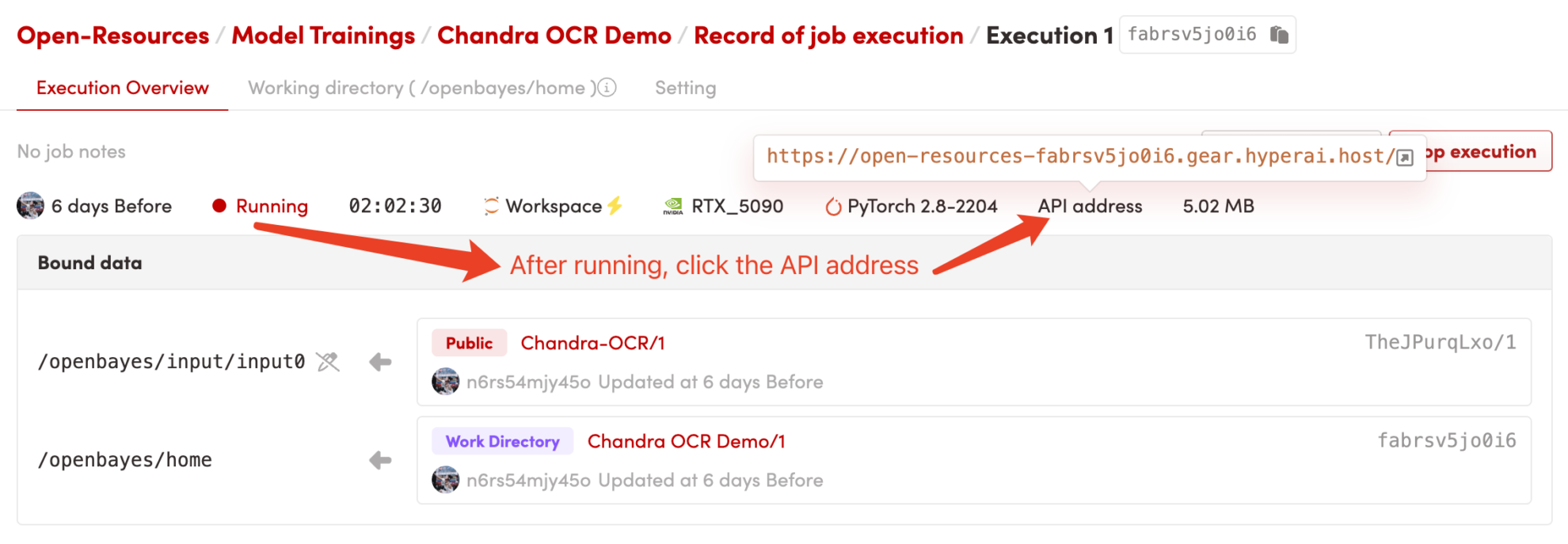
1. 启动容器或本地运行
启动容器后点击 API 地址即可进入 Web 界面:
2. 使用指南
若显示「Bad Gateway」, 表示模型正在初始化,请等待 1-2 分钟刷新页面。
提示:如果进入页面后显示「Running load_model()」,表示模型正在初始化,请耐心等待 1-2 分钟后刷新页面。


四、交流探讨
🖌️ 欢迎大家在平台内留言推荐或分享文档 OCR 、布局识别相关经验。可加入教程交流群,探讨 Chandra OCR 部署与应用技巧 ↓

Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.
AI Co-coding
Ready-to-use GPUs
Best Pricing
HyperAI Newsletters
订阅我们的最新资讯
我们会在北京时间 每周一的上午九点 向您的邮箱投递本周内的最新更新
邮件发送服务由 MailChimp 提供