Command Palette
Search for a command to run...
Dolphin Multimodal Document Image Parsing
1. Tutorial Introduction

Dolphin is a multimodal document parsing model launched by ByteDance in May 2025. This model is based on a two-stage approach: first, it generates a sequence of document layout elements; second, it uses these elements as anchors to parse the content in parallel. Dolphin performs exceptionally well on various document parsing tasks, outperforming models such as GPT-4.1 and Mistral-OCR. Related research papers are available. Dolphin: Document Image Parsing via Heterogeneous Anchor Prompting It has been accepted by ACL 2025.
This tutorial uses resources for a single RTX 4090 card.
2. Project Examples

3. Operation steps
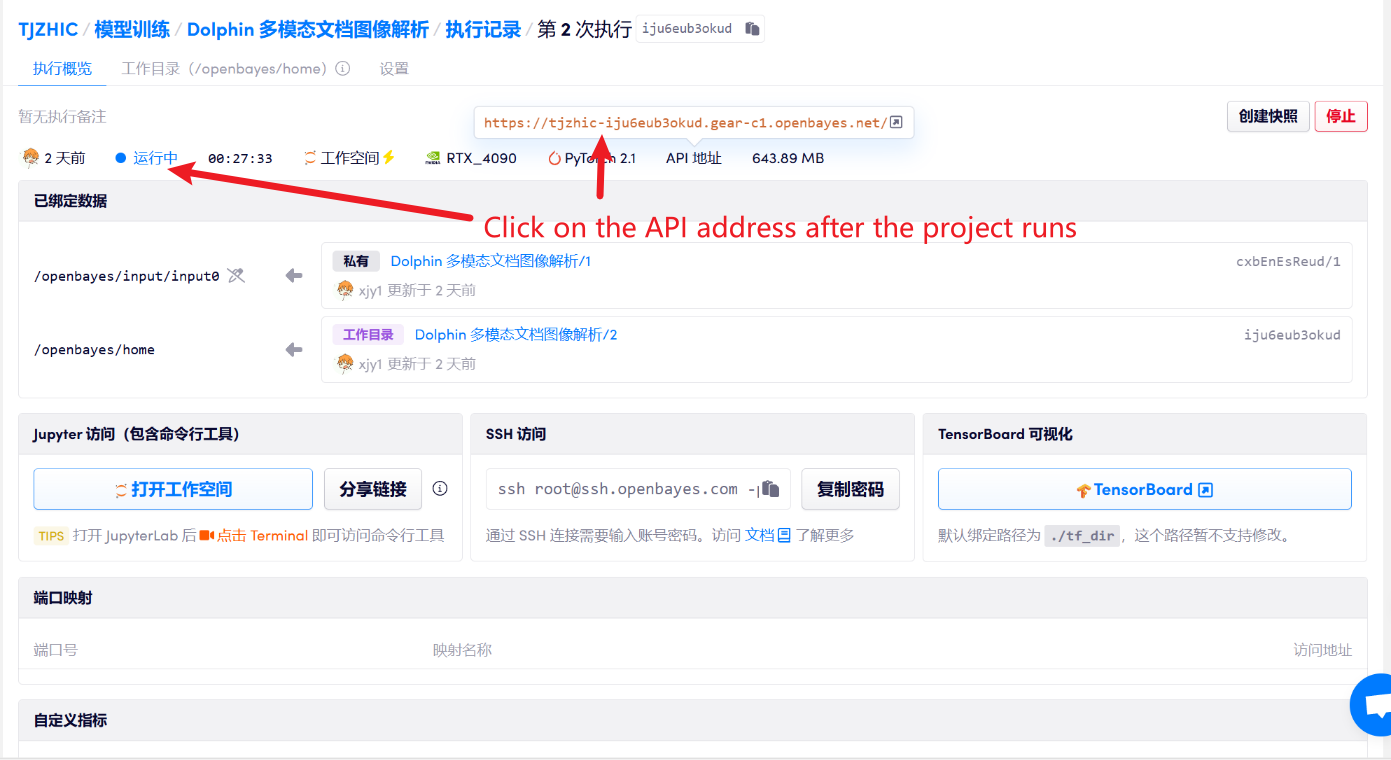
1. After starting the container, click the API address to enter the Web interface
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 1-2 minutes and refresh the page.
2. Usage Examples
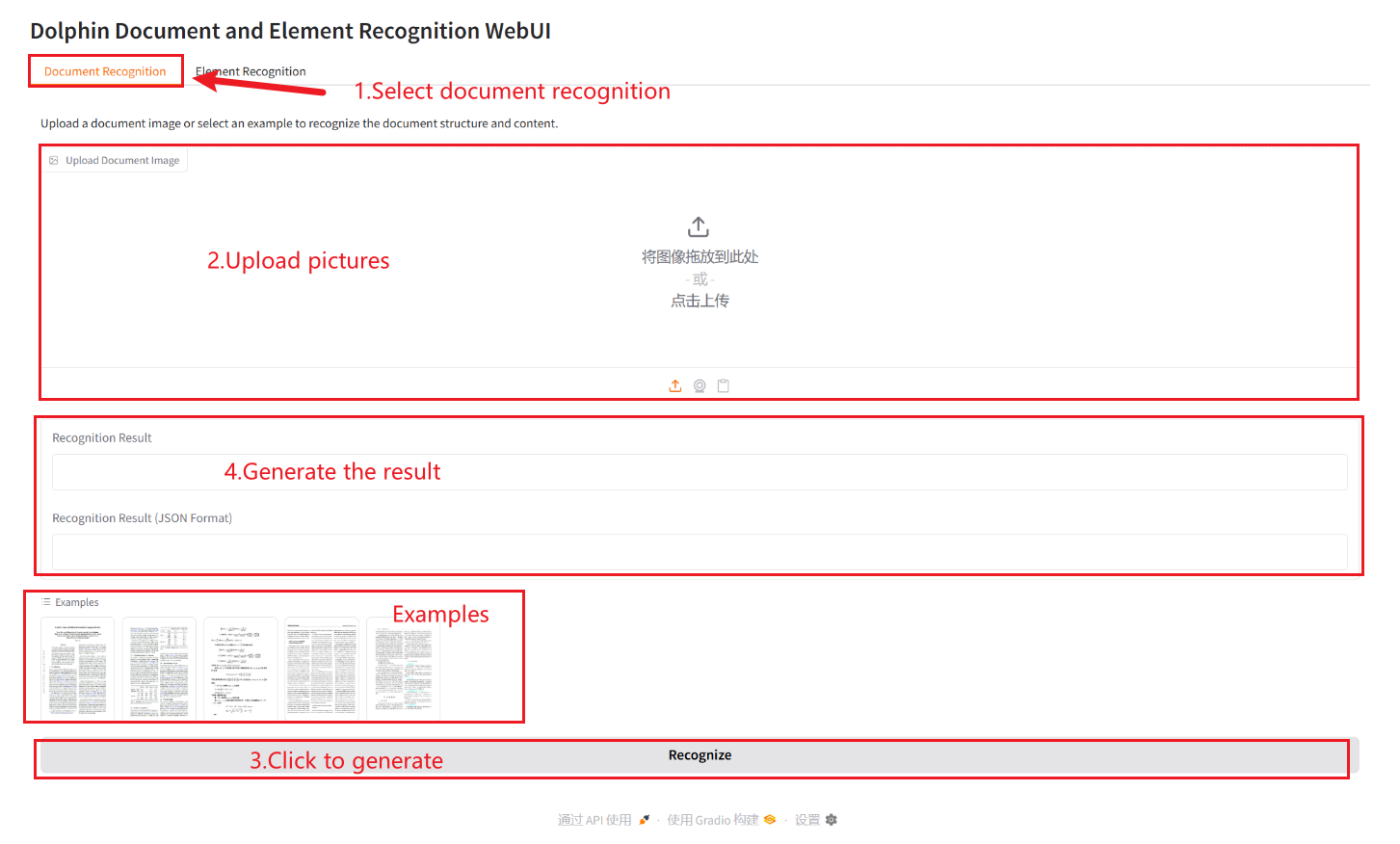
Document Recognition
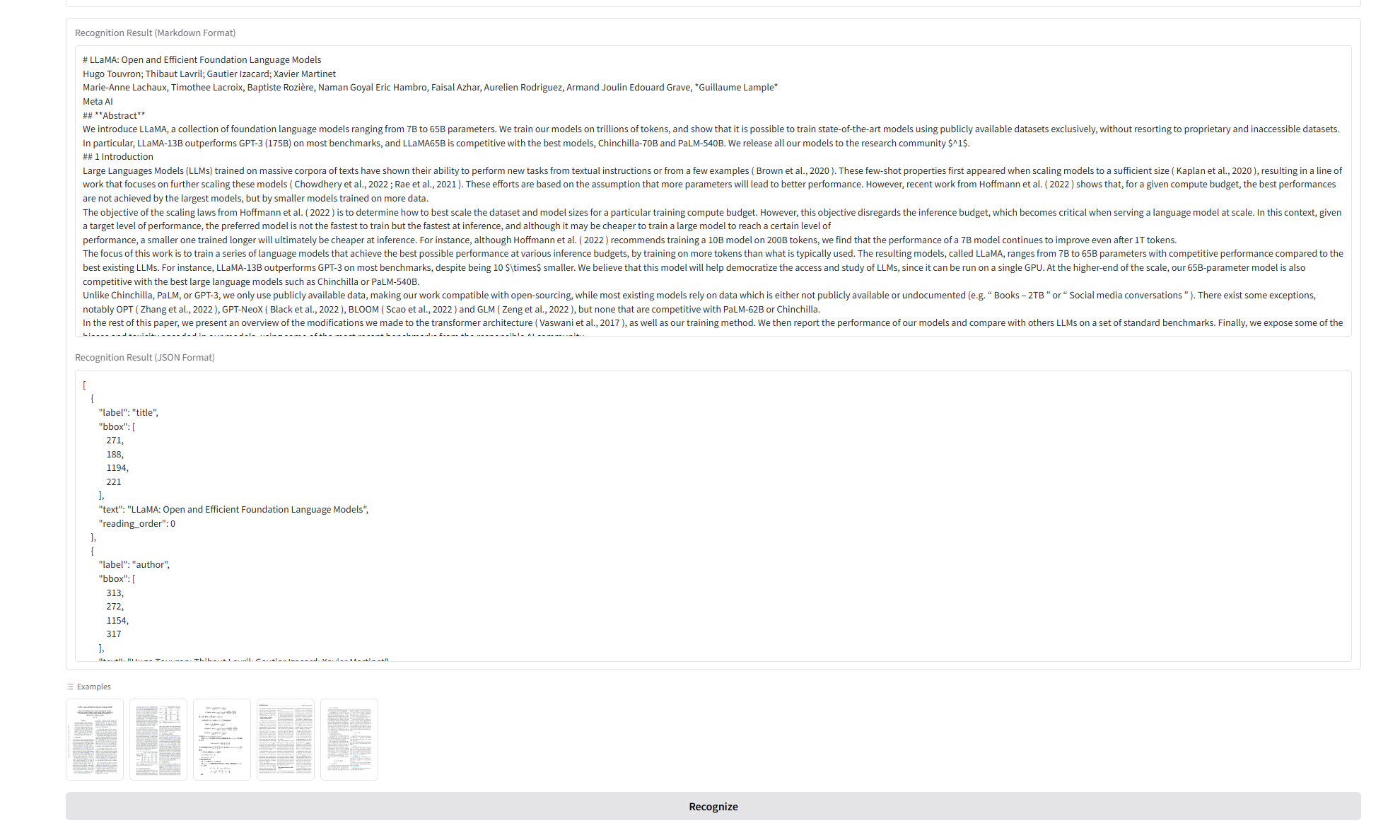
 result
result
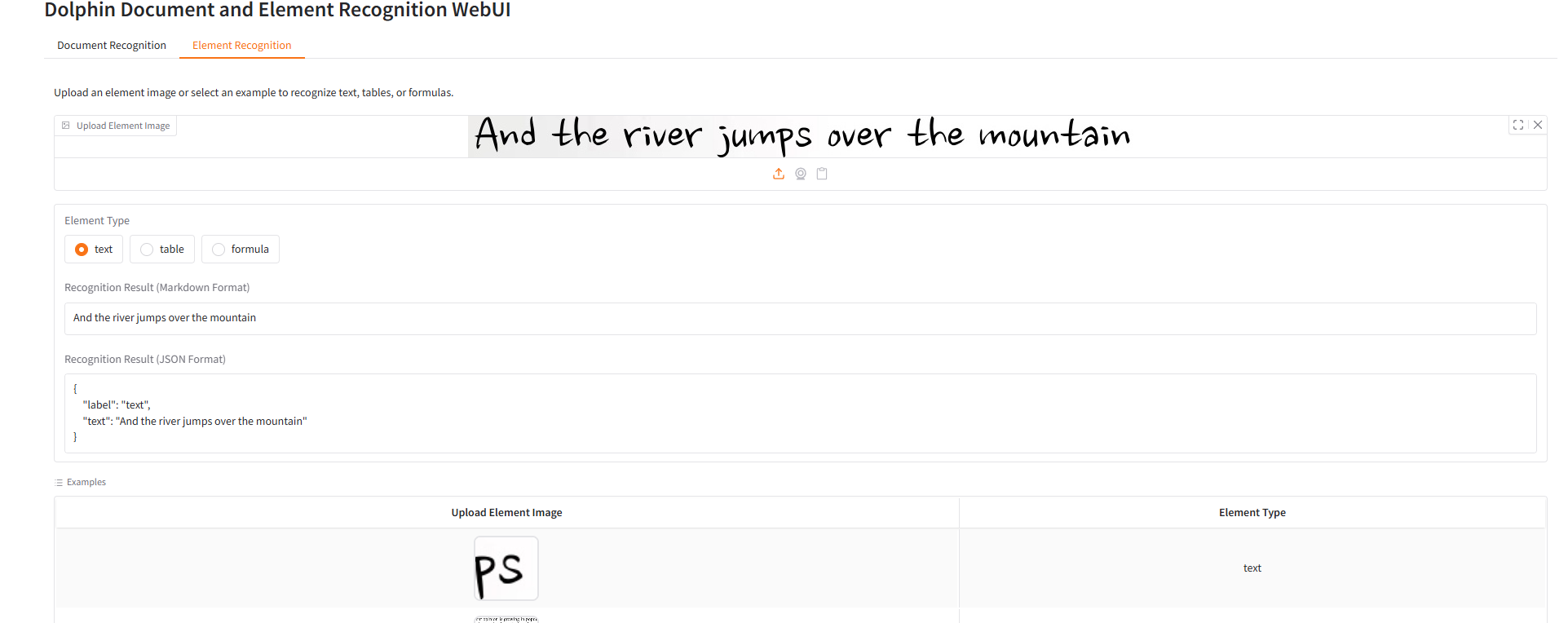
Element Recognition
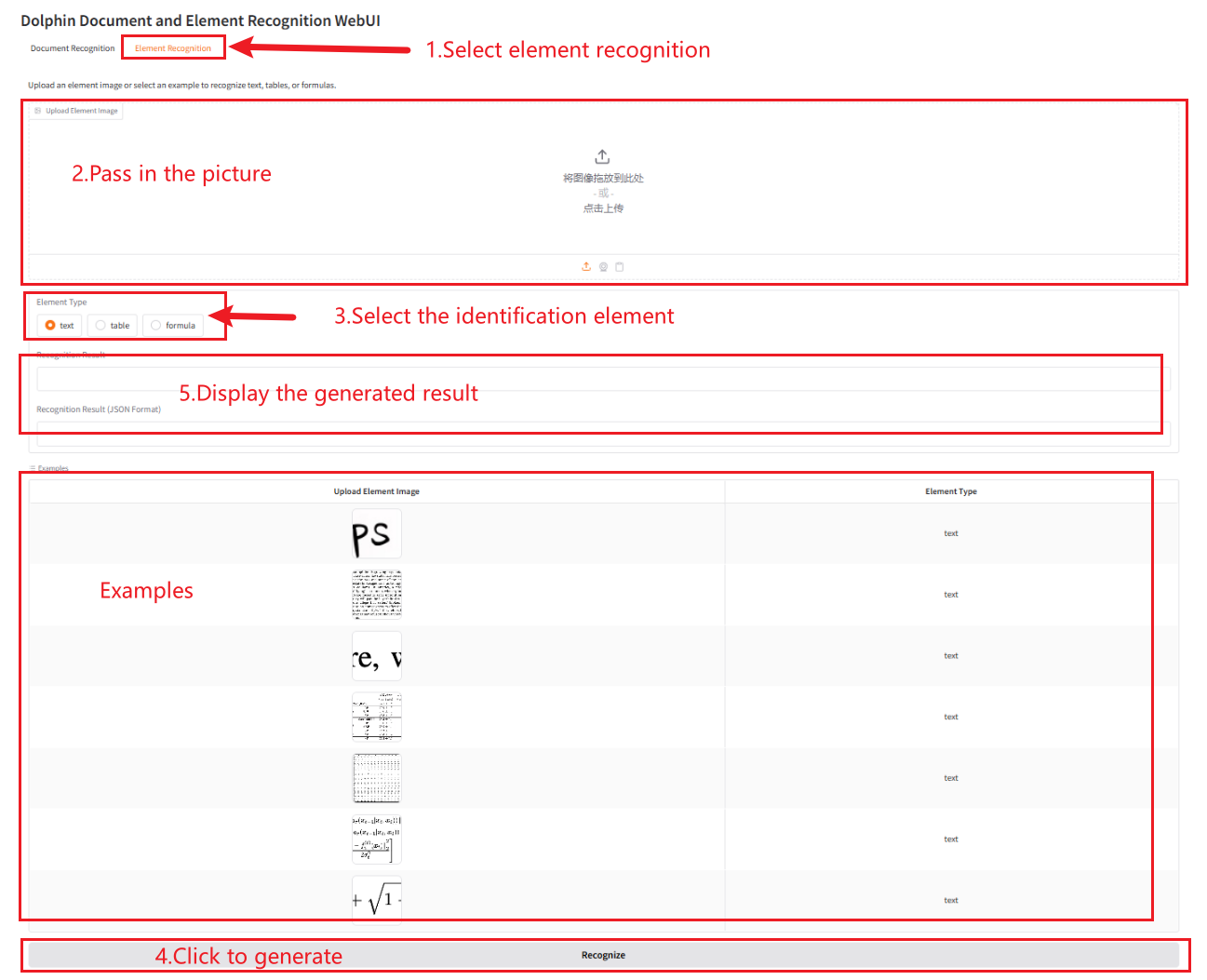
result
Citation Information
The citation information for this project is as follows:
@inproceedings{dolphin2025,
title={Dolphin: Document Image Parsing via Heterogeneous Anchor Prompting},
author={Feng, Hao and Wei, Shu and Fei, Xiang and Shi, Wei and Han, Yingdong and Liao, Lei and Lu, Jinghui and Wu, Binghong and Liu, Qi and Lin, Chunhui and Tang, Jingqun and Liu, Hao and Huang, Can},
year={2025},
booktitle={Proceedings of the 65rd Annual Meeting of the Association for Computational Linguistics (ACL)}
}Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.