Command Palette
Search for a command to run...
Describe Anything: Detailed Localized Image and Video Captioning
Describe Anything: Detailed Localized Image and Video Captioning
Abstract
Generating detailed and accurate descriptions for specific regions in images and videos remains a fundamental challenge for vision-language models. We introduce the Describe Anything Model (DAM), a model designed for detailed localized captioning (DLC). DAM preserves both local details and global context through two key innovations: a focal prompt, which ensures high-resolution encoding of targeted regions, and a localized vision backbone, which integrates precise localization with its broader context. To tackle the scarcity of high-quality DLC data, we propose a Semi-supervised learning (SSL)-based Data Pipeline (DLC-SDP). DLC-SDP starts with existing segmentation datasets and expands to unlabeled web images using SSL. We introduce DLC-Bench, a benchmark designed to evaluate DLC without relying on reference captions. DAM sets new state-of-the-art on 7 benchmarks spanning keyword-level, phrase-level, and detailed multi-sentence localized image and video captioning.
One-sentence Summary
The authors, affiliated with NVIDIA, UC Berkeley, and UCSF, propose Describe Anything Model (DAM), a novel framework for detailed localized captioning that combines a focal prompt and localized vision backbone to preserve fine-grained details and global context, leveraging a semi-supervised data pipeline to overcome data scarcity and achieving state-of-the-art performance on seven benchmarks across image and video captioning tasks.
Key Contributions
- Detailed localized captioning (DLC) remains challenging due to the trade-off between preserving fine-grained regional details and maintaining global context, which prior models often fail to balance when extracting features from global image representations or relying on coarse localization cues like bounding boxes.
- The Describe Anything Model (DAM) addresses this by introducing a focal prompt for high-density encoding of targeted regions and a localized vision backbone that integrates precise localization with contextual awareness, enabling rich, accurate descriptions even for small or non-salient objects.
- To overcome data scarcity, the authors propose DLC-SDP, a semi-supervised data pipeline that leverages segmentation datasets and self-training on web images to generate high-quality localized captions, and introduce DLC-Bench, a novel evaluation benchmark that assesses captions based on attribute-level correctness without relying on reference captions, enabling fairer and more comprehensive model evaluation.
Introduction
The authors address the challenge of generating detailed, accurate descriptions for specific regions in images and videos—a critical capability for fine-grained visual understanding and interactive AI systems. Prior vision-language models struggle with precise localization, often producing vague or contextually inaccurate captions due to either losing fine details when extracting regional features from global representations or relying on weak localization cues like bounding boxes. Additionally, existing datasets lack high-quality, detailed captions for non-salient or small regions, and standard benchmarks penalize models for correct details not present in sparse reference captions, leading to misleading evaluations. To overcome these issues, the authors introduce the Describe Anything Model (DAM), which combines a focal prompt for high-resolution encoding of user-specified regions and a localized vision backbone that preserves both local detail and global context. They further propose DLC-SDP, a semi-supervised data pipeline that leverages segmentation datasets and unlabeled web images to generate diverse, high-quality localized captions. Finally, they introduce DLC-Bench, a reference-free evaluation framework based on attribute-level scoring, enabling fairer assessment of detailed regional descriptions. Together, these contributions establish a new state-of-the-art in detailed localized captioning across images and videos.
Dataset
- The dataset is constructed via a two-stage semi-supervised learning pipeline (DLC-SDP), combining existing segmentation datasets with self-labeling to generate high-quality, detailed localized descriptions.
- Stage 1 uses four instance and semantic segmentation datasets, annotated with 603k regions across 202k images using off-the-shelf vision-language models (VLMs). An additional 81k instances from PACO are merged to enhance part description capabilities, resulting in 684k total annotated regions.
- Stage 2 involves self-labeling 10% of SA-1B, producing 774k annotations across 593k images. Instead of using the original masks, the authors use OWL-ViT v2 for open-vocabulary detection and SAM for mask generation, followed by instance segmentation via ViTDet + Cascade Mask R-CNN to filter out partial object masks.
- For each region, the authors use a cropped image and a masked image as input to the VLM, with the object category name included in the prompt to reduce ambiguity. The prompt includes detailed instructions such as “Describe the masked region in detail” and is augmented with 15 variations that condition on sentence or word count to improve generalization.
- Data quality is ensured through rejection sampling based on confidence scores from OWL-ViT v2, SAM, and SigLIP-based image-text similarity. Images are limited to at most two instances, and these must belong to different classes.
- The final training data consists of 1.5M samples, comparable in size to prior works like Ferret and RegionGPT, but with significantly better performance, demonstrating the effectiveness of the data pipeline.
- For video captioning, 94k regions across 37k videos from SA-V are annotated, with each region (masklet) representing an object across multiple frames. Instance segmentation is used to match masklets to full object instances, ensuring accurate labeling.
- During training, the model is fine-tuned on both image and video data using VILA 1.5’s recipe, treating videos as 8 concatenated frames. The 3B and 8B variants are trained for one epoch with batch sizes of 2048 and learning rates of 1e-4 and 1e-5, respectively, on 8 and 32 A100 GPUs.
- A focal crop strategy is applied, expanding the region by 1× width and height (up to 9× total area), with a minimum of 48 pixels in either dimension to preserve context for small regions.
- The model is trained with prompt augmentation, randomly selecting from 15 prompt variants that vary in phrasing and include conditional suffixes based on caption length, enhancing instruction-following and generalization.
Method
The authors leverage the Describe Anything Model (DAM) to generate detailed localized descriptions of user-specified regions within images and videos. DAM effectively balances local detail and contextual information through its proposed focal prompt and localized vision backbone. As shown in the framework diagram, DAM consists of two key components: the focal prompt and the localized vision backbone. The focal prompt is designed to provide a detailed representation of the region of interest within its broader context. It includes both the full image and a focal crop centered around the specified area, along with their corresponding masks. The authors first extract the bounding box B of the mask M and expand it by a factor α in both the horizontal and vertical directions to include additional surrounding context:
B′=ExpandBox(B,α).For instance, setting α=3 results in a region that can be up to 9 times as large as the original bounding box, subject to clipping at the image boundaries. If either the height or width of the expanded box is less than 48 pixels, a minimum size of 48 pixels is enforced in that dimension to ensure sufficient context for very small regions. The focal crop of the image and mask are then:
I′=I∣B′,M′=M∣B′,where ∣B′ denotes cropping to B′. The focal prompt thus consists of 1) the full image I and its mask M and 2) the focal crop I′ and its mask M′. By including both the full image and the focal crop, along with their masks, the focal prompt contains both global context and a detailed view of the region of interest.
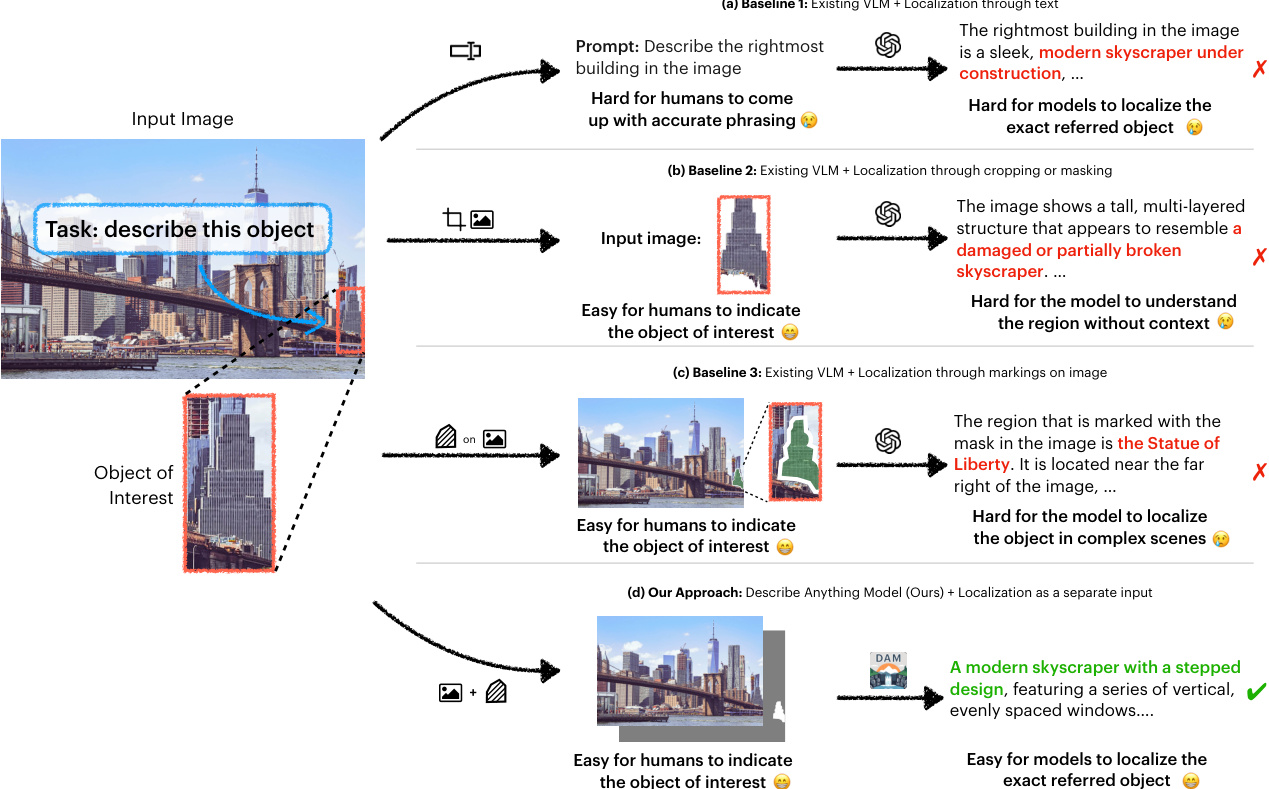
The localized vision backbone is designed to effectively process all four components of the focal prompt. The full image I and its mask M are processed through patch embedding layers, followed by the global vision encoder fG(⋅) to obtain global visual features z. The focal crop I′ and its mask M′ undergo a similar process with the regional vision encoder fR(⋅), except that fR(⋅) also takes z as a context to obtain the final fused visual features z′. Specifically, the authors have:
x=EI(I)+EM(M)+P,z=fG(x), x′=Ei(I′)+EM(M′)+P,z′=fR(x′,z),where EI(⋅) and EM(⋅) are the image and mask patch embedding layer, respectively, x and x′ are global and focal embedded inputs with information for both the image and the mask, and P denotes the positional encoding. The newly added mask embedding layer EM is initialized to output zeros, ensuring that the VLM's initial behavior is unaffected prior to fine-tuning.
To integrate global context into the region of interest, the authors insert gated cross-attention adapters into each transformer block of the regional vision encoder fR. After the self-attention and feed-forward layers, a gated cross-attention mechanism allows local features to attend to global features:
h(l)′=h(l)+tanh(γ(l))⋅CrossAttn(h(l),z) hAdapter(l)=h(l)′+tanh(β(l))⋅FFN(h(l)′),where h(l) is the output of the l-th self-attention block in fR, γ(l) and β(l) are learnable scaling parameters initialized to zero, and CrossAttn denotes cross-attention with queries from h(l) and keys and values from the global features z. hAdapter(l) is used in place of h(l) in the next Transformer block. To reduce the number of parameters, fR shares self-attention block weights with fG. By initializing γ(l) and β(l) to zero, the initial behavior of the model remains identical to the original VLM prior to fine-tuning. During training, the model learns to leverage the global context to enhance local feature representations, facilitating detailed and contextually accurate descriptions.
The visual features from both the global and regional vision encoders are combined and fed into the large language model to generate detailed, context-aware descriptions T:
T=LLM(t,z′),where t denotes textual prompt tokens. Notably, the proposed components do not increase the sequence length of the vision tokens, ensuring that DAM remains efficient. By initializing new modules (mask embedding EM and scaling parameters γ(l) and β(l)) to zeros, the model preserves the pre-trained capabilities of the VLM prior to fine-tuning, allowing for smooth adaptation of an off-the-shelf VLM without rerunning pre-training. Thanks to this design, the model requires way less training data (∼1.5M samples) than prior works that involve VLM pretraining.
The model naturally extends to handling videos by processing sequences of frames and their corresponding masks. The visual features from all frames are concatenated in the sequence dimension and fed into the language model to generate detailed localized descriptions across the video frames, compatible with how VLMs are pretrained to handle videos. The authors leverage SAM 2 [62] to turn sparse localizations into a mask for each frame.
Experiment
- DLC-Bench evaluates detailed localized captioning (DLC) by using LLM-based positive and negative questions to assess accuracy and hallucination avoidance, without relying on reference captions.
- On PACO, DAM achieves 73.2% semantic IoU and 84.2% semantic similarity, surpassing the previous best by 23.2% and 8.5% respectively.
- On Ref-L4, DAM achieves 33.4% relative improvement on short language-based metrics and 13.1% on long language-based metrics.
- On the proposed DLC-Bench, DAM outperforms existing open-source and API-only models, including GPT-4o and o1, with state-of-the-art positive and negative accuracy.
- On HC-STVG, DAM achieves 19.8% relative improvement over the previous best, including concurrent work VideoRefer.
- On VideoRefer-Bench, DAM surpasses prior methods in both zero-shot and in-domain settings, demonstrating strong generalization.
- Ablations show that focal prompting with cross-attention and local crops significantly improves performance, achieving 67.3% accuracy.
- Data scaling and semi-supervised learning (SSL) further enhance performance, with SSL improving accuracy to 67.3% using 10% unannotated SA-1B data.
The authors use the SA-V dataset, which contains 36,922 videos and 93,969 regions, for training detailed localized video captioning. This dataset provides a large-scale source of video regions for evaluating and improving models in understanding and describing objects across multiple frames.
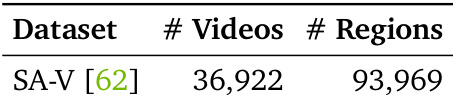
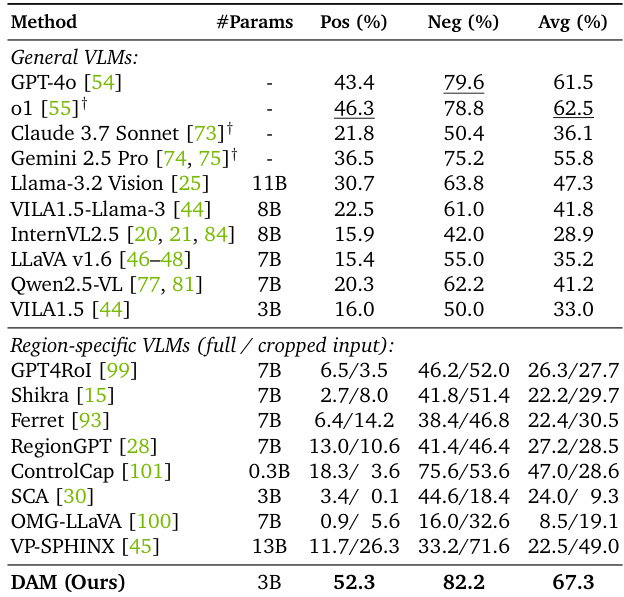
The authors use DLC-Bench to evaluate detailed localized captioning models, assessing their ability to include correct details and exclude irrelevant or incorrect information. Results show that DAM achieves the highest average accuracy of 67.3%, outperforming other general and region-specific VLMs, with strong positive and negative accuracy scores.
The authors use the LVIS benchmark to evaluate their model's performance on open-class keyword-level localized captioning, showing that adding additional datasets improves the positive accuracy from 34.0% to 47.5% and the average accuracy from 53.3% to 63.8%. Further incorporating semi-supervised learning on 10% of SA-1B images increases the average accuracy to 67.3%, demonstrating the benefits of data scaling and diverse training data.

The authors use DLC-Bench to evaluate detailed localized captioning, where models are scored based on their ability to include correct details and exclude irrelevant or incorrect information. Results show that DAM achieves state-of-the-art performance across multiple benchmarks, including 73.2% semantic IoU and 84.2% semantic similarity on PACO, and significantly outperforms existing models on DLC-Bench with high positive and negative accuracy.

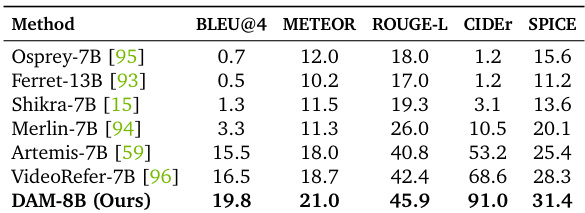
Results show that DAM-8B achieves state-of-the-art performance across multiple metrics, outperforming previous models such as Osprey-7B and Ferret-13B on BLEU@4, METEOR, ROUGE-L, CIDEr, and SPICE. The model demonstrates superior captioning quality, particularly in detailed and localized descriptions, with significant improvements in both short and long language-based evaluation metrics.