Command Palette
Search for a command to run...
GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable
Reinforcement Learning
GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
Abstract
We present GLM-4.1V-Thinking and GLM-4.5V, a family of vision-language models (VLMs) designed to advance general-purpose multimodal understanding and reasoning. In this report, we share our key findings in the development of the reasoning-centric training framework. We first develop a capable vision foundation model with significant potential through large-scale pre-training, which arguably sets the upper bound for the final performance. We then propose Reinforcement Learning with Curriculum Sampling (RLCS) to unlock the full potential of the model, leading to comprehensive capability enhancement across a diverse range of tasks, including STEM problem solving, video understanding, content recognition, coding, grounding, GUI-based agents, and long document interpretation. In a comprehensive evaluation across 42 public benchmarks, GLM-4.5V achieves state-of-the-art performance on nearly all tasks among open-source models of similar size, and demonstrates competitive or even superior results compared to closed-source models such as Gemini-2.5-Flash on challenging tasks including Coding and GUI Agents. Meanwhile, the smaller GLM-4.1V-9B-Thinking remains highly competitive-achieving superior results to the much larger Qwen2.5-VL-72B on 29 benchmarks. We open-source both GLM-4.1V-9B-Thinking and GLM-4.5V. Code, models and more information are released at https://github.com/zai-org/GLM-V.
One-sentence Summary
The GLM-V Team from Zhipu AI and Tsinghua University propose GLM-4.1V-Thinking and GLM-4.5V, vision-language models enhanced by a reasoning-centric training framework featuring Reinforcement Learning with Curriculum Sampling, enabling state-of-the-art open-source performance on 42 benchmarks, outperforming larger models like Qwen2.5-VL-72B and competing with closed-source counterparts such as Gemini-2.5-Flash in coding, GUI agents, and long-document understanding.
Key Contributions
-
The paper introduces GLM-4.1V-Thinking and GLM-4.5V, a family of vision-language models designed to enhance general-purpose multimodal reasoning, with a focus on overcoming the limitations of prior models that excel only in narrow domains or lack scalable reasoning capabilities.
-
The authors propose Reinforcement Learning with Curriculum Sampling (RLCS), a multi-domain reinforcement learning framework that dynamically selects tasks based on model competence, enabling efficient and stable training that significantly boosts performance across diverse tasks including STEM reasoning, coding, GUI agents, and long document understanding.
-
In evaluations across 42 public benchmarks, GLM-4.5V achieves state-of-the-art results among open-source models of similar size and matches or exceeds the performance of closed-source models like Gemini-2.5-Flash, while the smaller GLM-4.1V-9B-Thinking outperforms much larger models such as Qwen2.5-VL-72B on 29 benchmarks.
Introduction
Vision-language models (VLMs) are essential for intelligent systems that interpret both visual and textual information, with growing demand for advanced reasoning across diverse tasks such as scientific problem solving, autonomous agent development, and complex document understanding. Prior approaches to enhancing VLM reasoning have often been limited to specific domains or failed to scale effectively, and the open-source community lacked a general-purpose multimodal reasoning model that consistently outperforms non-thinking baselines of similar size. The authors introduce GLM-4.1V-Thinking and GLM-4.5V, a new family of VLMs designed for versatile, general-purpose reasoning through a unified training framework centered on scalable reinforcement learning. Their key innovation is Reinforcement Learning with Curriculum Sampling (RLCS), a multi-domain RL strategy that dynamically selects tasks based on model competence, improving training efficiency and cross-domain generalization. The models are trained on a diverse, knowledge-intensive multimodal dataset and fine-tuned with structured reasoning prompts, resulting in state-of-the-art performance across 42 benchmarks—surpassing larger models like Qwen-2.5-VL-72B and matching or exceeding closed-source Gemini-2.5-Flash. The authors open-source multiple variants, including a 9B parameter thinking model and a 106B total parameter model with 12B activated parameters, along with pre-trained bases and domain-specific reward systems, enabling broader research and development in multimodal reasoning.
Dataset
-
The dataset is composed of multiple high-quality, curated data sources across five core modalities: image captioning, interleaved image-text, OCR, visual grounding, video, and instruction tuning data.
-
Image caption data originates from over 10 billion image-text pairs aggregated from LAION, DataComp, DFN, Wukong, and web search engines. It undergoes a four-stage refinement: heuristic filtering (resolution, color, length, deduplication), CLIP-based relevance filtering (score > 0.3), concept-balanced resampling to address long-tail distributions, and factual-centered recaptioning via an iterative model to improve caption quality. The final dataset merges original and recaptioned data at a fixed ratio.
-
Interleaved image-text data is extracted from web sources (MINT, MMC4, OmniCorpus) and digitized academic books. Web data is cleaned using CLIP-Score thresholds, heuristic rules, and a custom image classifier to remove ads and QR codes. A high-knowledge-density classifier identifies informative images (e.g., charts, diagrams). Academic books are filtered for STEM relevance and parsed using PDF tools to extract structured image-text pairs.
-
OCR data comprises 220 million images from three sources: synthetic document images (rendered text on LAION backgrounds), natural scene text (Paddle-OCR with bounding box filtering), and academic documents (arXiv papers processed via LaTeX2XML, HTML parsing, and rasterization into paired PDF renderings and markup).
-
Grounding data includes 40 million natural image annotations from LAION-115M using GLIPv2 to predict bounding boxes for noun phrases (retaining samples with at least two boxes), and over 140 million GUI-specific QA pairs generated via Playwright-driven web interaction, capturing DOM elements and precise bounding boxes for Referring Expression tasks.
-
Video data is built from academic, web, and proprietary sources, with fine-grained human annotation for actions, in-scene text, camera motion, and shot composition. A multimodal embedding-based deduplication strategy removes semantically redundant pairs, ensuring data purity.
-
Instruction tuning data includes 50 million samples covering visual perception, multimodal reasoning (e.g., STEM), document understanding, GUI operations, and UI coding. It is diversified using a fine-grained taxonomy, augmented with synthetic data for complex scenarios (e.g., GUI interactions), and rigorously checked for contamination from public benchmarks.
-
For supervised fine-tuning, a 50 million sample reasoning dataset is created with a standardized response format: </tool_call> {think_content} </tool_call> {answer_content} . Verifiable tasks require final answers enclosed in <begin_of_box> and <end_of_box>. Special tokens are added to the tokenizer for parsing. The dataset is cleaned to enforce formatting, remove mixed-language content, and eliminate noisy reasoning patterns.
-
Data preparation follows a structured pipeline: task identification (e.g., temporal grounding over open-ended captioning), data curation (converting multiple-choice to fill-in-the-blank), quality validation (pass@k evaluation and human difficulty grading), and pilot RL experiments to confirm data utility and model improvement potential.
-
The final training mix uses a balanced combination of these datasets, with specific ratios tuned for model performance. Processing includes cropping strategies (e.g., focusing on informative image regions), metadata construction (e.g., structured DOM and bounding box annotations), and iterative enhancement by incorporating high-quality RL-generated examples into the cold-start dataset.
Method
The authors leverage a modular architecture for GLM-4.1V-Thinking and GLM-4.5V, designed to process diverse multimodal inputs including images, videos, and text. The framework consists of three primary components: a vision encoder, an MLP projector, and a large language model (LLM) decoder. The vision encoder, based on a Vision Transformer (ViT), processes visual inputs and is initialized with AIMv2-Huge. To support arbitrary image resolutions and aspect ratios, the model integrates 2D-RoPE into the ViT's self-attention layers, enabling effective handling of extreme aspect ratios and high resolutions. Additionally, the model retains the original learnable absolute position embeddings, which are dynamically adapted to variable-resolution inputs through bicubic interpolation. This adaptation involves normalizing patch coordinates to a continuous grid spanning [−1,1], and then sampling from the original position embedding table using a bicubic interpolation function to generate the final adapted embedding for each patch.

For video inputs, the model employs temporal downsampling by a factor of two, achieved through a strategy similar to Qwen2-VL, which replaces the original 2D convolutions with 3D convolutions. This allows the model to efficiently process video sequences. To enhance temporal understanding, time index tokens are inserted after each frame token, with the time index encoded as a string representing the frame's timestamp. This design explicitly informs the model of the real-world timestamps and temporal distances between frames, thereby improving its temporal grounding capabilities. The MLP projector aligns the visual features extracted by the ViT encoder to the textual token space, enabling the integration of visual and textual information. The LLM decoder, which serves as the language model, processes the multimodal tokens and generates token completions. The authors extend RoPE to 3D-RoPE in the LLM to further enhance spatial awareness on the language side, providing superior spatial understanding for multimodal contexts while preserving the original model's text-related capabilities.
Experiment
- Conducted full-parameter fine-tuning with 32,768-token sequence length and global batch size of 32, using diverse long-form reasoning data across multiple domains, including math, multi-turn conversation, agent planning, and instruction following. Mixed thinking and non-thinking modes via special token /nothink, with non-thinking mode trained using content from thinking examples, achieving better performance than curated subsets.
- Employed Reinforcement Learning with Verifiable Rewards (RLVR) and Reinforcement Learning with Human Feedback (RLHF) across all multimodal domains, including STEM, OCR, video understanding, GUI agents, and logical reasoning, to enhance model capabilities.
- Identified key stability factors in RL: high-quality cold-start SFT data is critical; removed entropy loss to prevent garbled outputs; used top-p = 1 for stable rollouts; adopted per-sample loss computation for more stable training; emphasized learning output format during SFT rather than relying on RL.
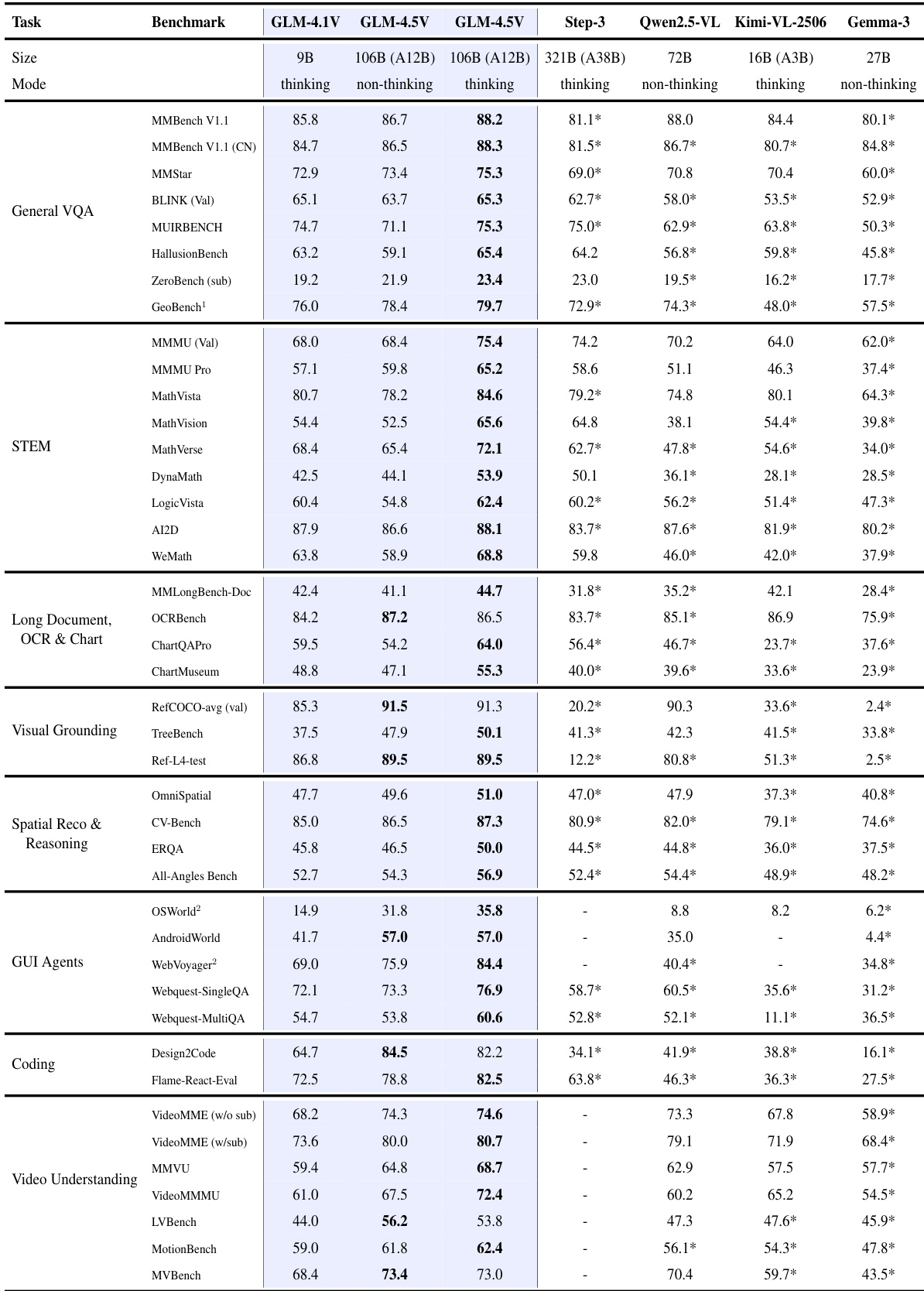
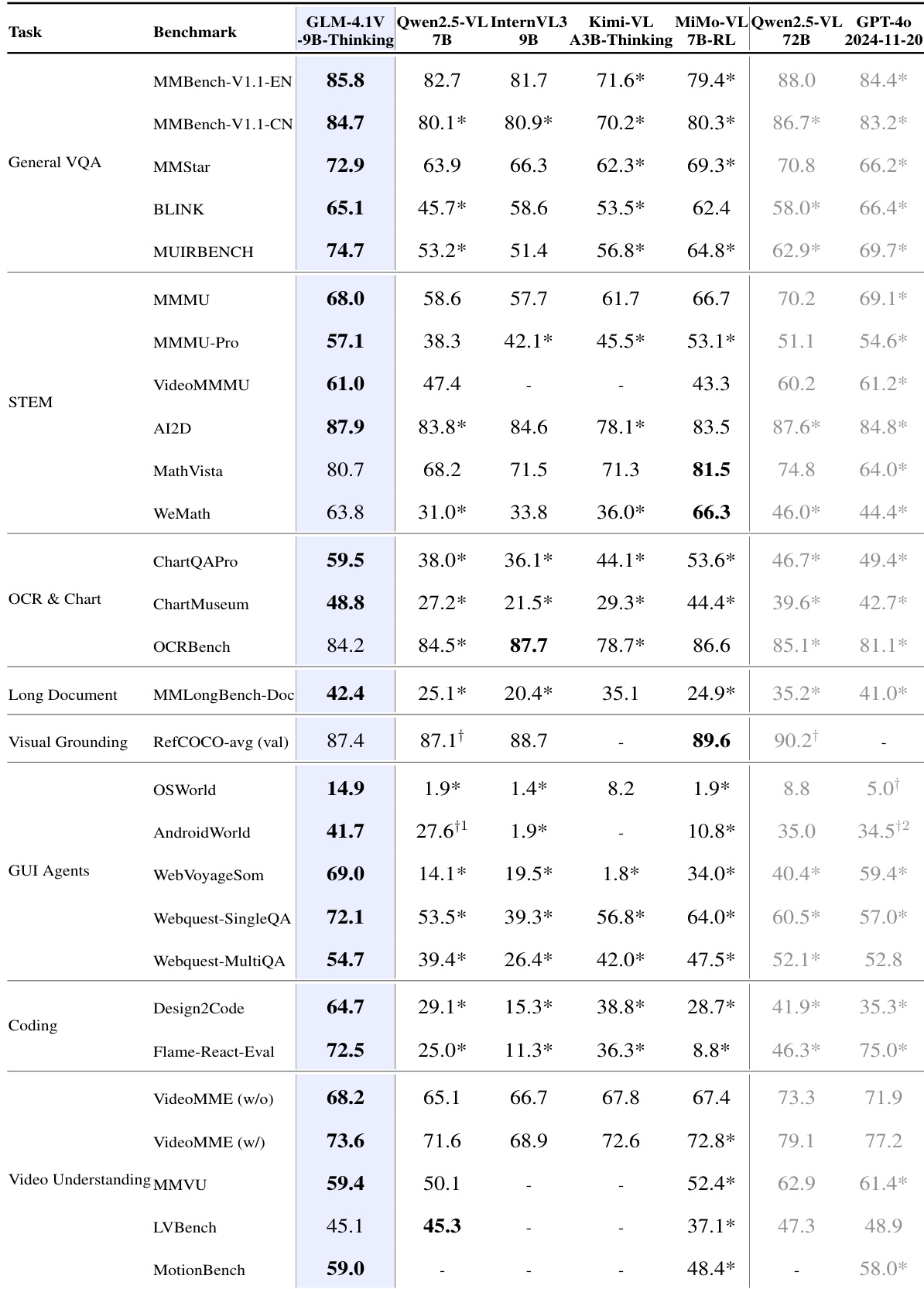
- Evaluated GLM-4.5V on 42 public benchmarks across eight categories: General VQA, STEM, OCR & Document, Visual Grounding, Spatial Reasoning, GUI Agents, Coding, and Video Understanding, using vLLM and SGLang for inference, with 8,192-token output limit and boxed answer extraction.
- On all benchmarks, GLM-4.5V achieved state-of-the-art performance among open-source models, outperforming models like Qwen-VL, Kimi-VL, and Gemma-3, particularly excelling in STEM (MMMU, AI2D), OCR & Document (ChartQAPro, MMLongBench-Doc), GUI Agents, and Video Understanding (VideoMME, MMVU).
- GLM-4.1V-9B-Thinking surpassed the larger Qwen2.5-VL-72B model on 29 out of 42 benchmarks, including challenging tasks like MMMU Pro and ChartMuseum, demonstrating superior efficiency and performance.
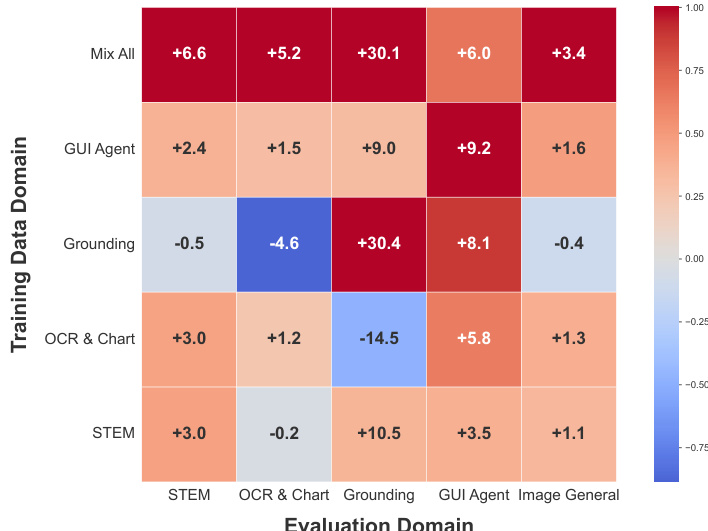
- Cross-domain RL experiments revealed strong mutual facilitation: training on one domain (e.g., STEM, OCR & Chart, GUI agents) improved performance across others, with GUI-agent RL boosting all domains, indicating shared underlying capabilities. Joint training on all domains yielded the highest gains in STEM, OCR & Chart, and general VQA, though grounding and GUI-agent performance did not improve, suggesting need for specialized strategies.
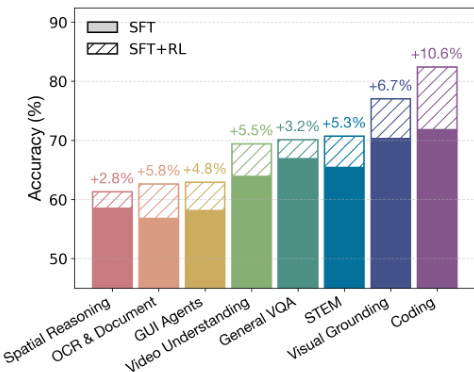
The authors use a bar chart to show the performance improvement of GLM-4.5V after reinforcement learning (RL) across multiple multimodal domains. Results show that the SFT+RL phase consistently boosts accuracy over the SFT-only baseline, with the largest gains observed in Coding (+10.6%), Visual Grounding (+6.7%), and STEM (+5.3%). The improvements across all domains indicate that RL effectively enhances the model's capabilities in reasoning, perception, and cross-modal understanding.
The authors use a comprehensive set of 42 benchmarks across eight categories to evaluate GLM-4.5V and GLM-4.1V-Thinking, comparing them against several open-source models. Results show that GLM-4.5V achieves state-of-the-art performance across all benchmarks, demonstrating consistent superiority in multimodal reasoning, particularly in STEM, OCR & document understanding, and GUI agents.
The authors use a comprehensive set of 42 benchmarks across eight categories to evaluate GLM-4.5V and GLM-4.1V-Thinking, comparing them against several open-source models. Results show that GLM-4.5V achieves state-of-the-art performance across all benchmarks, demonstrating strong multimodal reasoning and generalization capabilities.
The authors use a multi-domain reinforcement learning setup to evaluate cross-domain generalization in GLM-4.1V-9B-Thinking, training the model on individual domains and assessing performance across all domains. Results show that training on one domain improves performance in others, with the "Mix All" configuration yielding the highest gains in STEM, OCR & Chart, and general VQA, indicating strong mutual facilitation across domains.