Command Palette
Search for a command to run...
Ovis-Image Technical Report
Ovis-Image Technical Report
Abstract
We introduce extbfOvis−Image, a 7B text-to-image model specifically optimized for high-quality text rendering, designed to operate efficiently under stringent computational constraints. Built upon our previous Ovis-U1 framework, Ovis-Image integrates a diffusion-based visual decoder with the stronger Ovis 2.5 multimodal backbone, leveraging a text-centric training pipeline that combines large-scale pre-training with carefully tailored post-training refinements. Despite its compact architecture, Ovis-Image achieves text rendering performance on par with significantly larger open models such as Qwen-Image and approaches closed-source systems like Seedream and GPT4o. Crucially, the model remains deployable on a single high-end GPU with moderate memory, narrowing the gap between frontier-level text rendering and practical deployment. Our results indicate that combining a strong multimodal backbone with a carefully designed, text-focused training recipe is sufficient to achieve reliable bilingual text rendering without resorting to oversized or proprietary models.
One-sentence Summary
The authors from Alibaba Group's Ovis Team propose Ovis-Image, a 7B text-to-image model that achieves state-of-the-art bilingual text rendering by integrating a diffusion-based visual decoder with the Ovis 2.5 multimodal backbone and a text-centric training pipeline, enabling high-quality generation on a single GPU while matching larger open and closed-source models.
Key Contributions
-
Ovis-Image is a 7B text-to-image model specifically optimized for high-quality text rendering, achieving performance on par with much larger 20B-class open models like Qwen-Image and approaching state-of-the-art closed-source systems such as GPT4o, all while maintaining a compact, deployable architecture.
-
The model leverages the strong Ovis 2.5 multimodal backbone and a diffusion-based visual decoder with a text-centric training pipeline, enabling accurate, legible, and semantically consistent bilingual text rendering in complex, layout-sensitive scenarios such as posters, UI mockups, and infographics.
-
Designed for efficiency, Ovis-Image runs on a single high-end GPU with moderate memory, supporting low-latency interactive use and batch serving, thus bridging the gap between frontier-level text rendering and practical deployment in real-world applications.
Introduction
The authors leverage recent advances in text-to-image generation to address the persistent challenge of high-quality, low-cost text rendering within synthetic images. While state-of-the-art models achieve strong text fidelity, they often rely on massive parameter counts or closed-source architectures, limiting deployability and reproducibility. Prior open models, including the authors’ own 3B Ovis-U1, struggle with text artifacts and hallucinations despite efficient design. To bridge this gap, the authors introduce Ovis-Image, a 7B parameter model that combines a powerful multimodal backbone (Ovis 2.5) with a diffusion-based visual decoder. By focusing on text rendering while maintaining strong general image synthesis, Ovis-Image achieves performance on par with 20B-class open models and near-state-of-the-art closed-source systems, delivering sharp, semantically accurate text in practical applications like UI mockups and signage, all with acceptable computational cost.
Dataset
-
The dataset for Ovis-Image is composed of a diverse mixture of web-scale, licensed, and synthetic image-text pairs, sourced from public web crawls, curated collections, and synthetic generation. It includes everyday photographs, illustrations, design assets, UI mockups, and content where text is a salient visual element such as posters, banners, logos, and UI layouts.
-
For pre-training, the corpus is large and heterogeneous, with extensive recaptioning in both Chinese and English to improve text-image alignment. A multi-stage filtering pipeline removes corrupted images, mismatched or uninformative captions, and unsafe content. Coarse deduplication reduces near-duplicates. Synthetic data is added via a rendering engine to generate clean typographic text in varied fonts, sizes, and placements, enhancing coverage of text rendering scenarios.
-
Supervised fine-tuning uses a higher-quality subset with a focus on clean visuals and well-structured prompts. Images are predominantly high-resolution (typically 1024 pixels) and span a broad range of aspect ratios to reflect real-world usage. The data includes a moderate amount of synthetic content to improve detail, layout control, and coverage of rare concepts. Simple balancing across content type, resolution, and aspect ratio prevents overfitting.
-
For DPO (Direct Preference Optimization), a preference dataset is built on top of the supervised fine-tuning distribution. Around 90% of the data consists of high-quality, aesthetically pleasing images from common object categories and everyday scenes, pre-filtered using automated scorers like HPSv3, CLIP, and PickScore. The remaining 10% comes from an in-house collection of design and creative content, including posters and stylized compositions. For each prompt, one high-quality image is selected from the pool, and a second candidate is generated using the SFT model. Both are scored by multiple models, and the higher-scoring image is labeled as the preferred (winner) option, forming a preference pair.
-
All data undergoes consistent processing, including metadata construction for source tracking and filtering, and cropping is applied selectively during training to ensure visual content remains central, especially in synthetic and layout-heavy data.
Method
The authors leverage a modular, diffusion-based architecture to achieve high-quality text rendering within a compact 7B parameter footprint. The overall framework, illustrated in the figure below, builds upon the Ovis-U1 foundation while enhancing the visual decoder and streamlining the design for improved efficiency and text-centric performance.
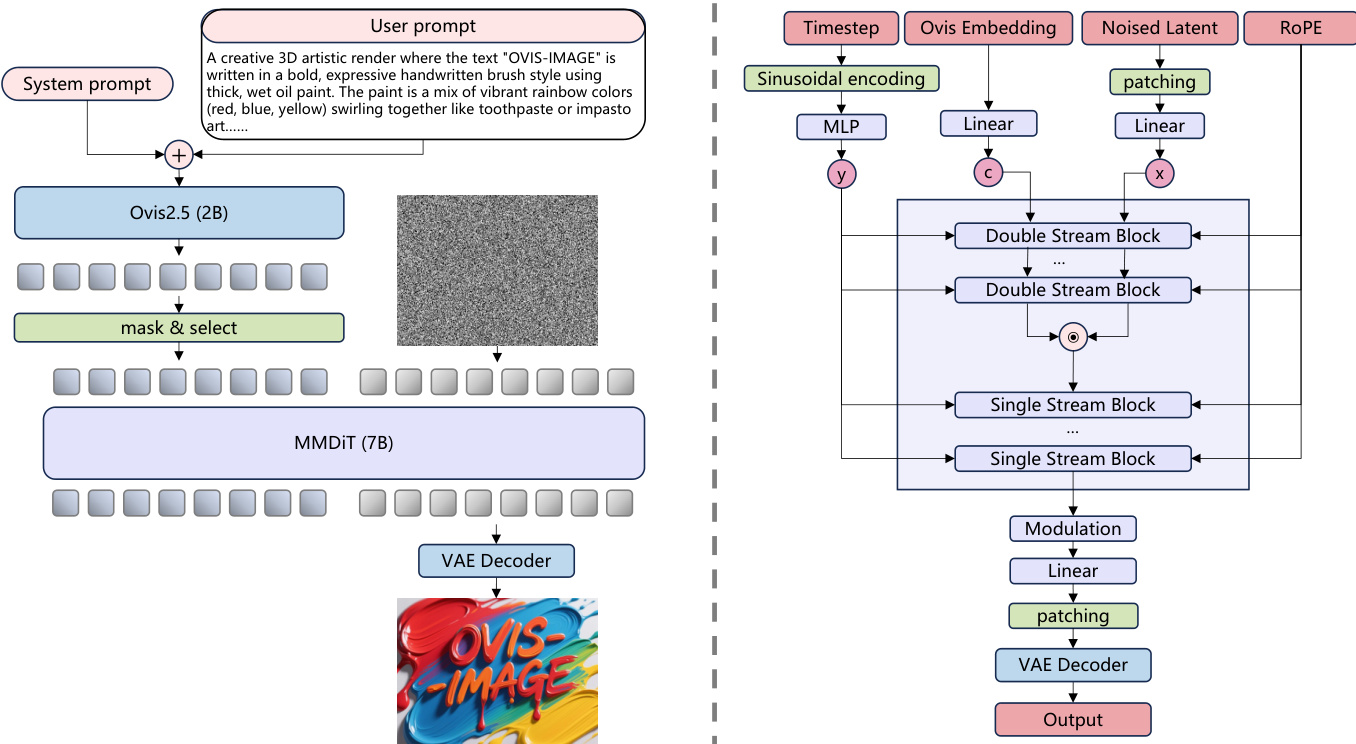
The architecture consists of a text encoder, a visual decoder, and a variational autoencoder (VAE) for latent space manipulation. The text encoder is based on the Ovis 2.5-2B model, which is specifically trained on multimodal data to ensure strong alignment between textual and visual representations. This encoder processes the user prompt and generates embeddings that condition the image generation process. Unlike the Ovis-U1 framework, Ovis-Image simplifies the architecture by removing the refiner structure and directly utilizing the final hidden states of the Ovis encoder as conditioning inputs for the image decoder.
The visual decoder is implemented as a modified MMDiT (Multimodal Diffusion Transformer) with 7B parameters, which serves as the core generative component. This decoder is built upon the MMDiT framework, incorporating RoPE (Rotary Positional Embedding) for enhanced positional encoding. The architecture features a hybrid block structure, including six double-stream blocks and 27 single-stream blocks, designed to efficiently process both text and visual information. To increase model capacity, the number of attention heads is set to 24, and the SwiGLU activation function is employed. The MMDiT processes the text embeddings and a noisy latent representation of the image, iteratively refining the latent space through a series of attention and feed-forward layers.
The VAE model, sourced from FLUX.1-schnell, is used to encode and decode images into and from a lower-dimensional latent space. This component is kept frozen throughout training, allowing the model to focus on learning the generative process within the latent domain. The VAE decoder reconstructs the final image from the refined latent representation produced by the MMDiT.
The training process follows a four-stage pipeline designed to progressively refine the model's capabilities. The first stage is pretraining, where the MMDiT is initialized randomly and trained on a diverse dataset of images using a standard noise-prediction loss. This stage establishes a robust foundation for general image generation. The second stage is supervised fine-tuning, where the model is further trained on instruction-style data to improve its ability to interpret and adhere to user prompts, particularly those involving text rendering. The third stage employs Direct Preference Optimization (DPO) to align the model with human preferences, using a mixture of human and model-generated preference data. This stage enhances the model's helpfulness, harmlessness, and adherence to prompt details, including text layout and rendering. The final stage utilizes Group Relative Policy Optimization (GRPO) to further refine the model through on-policy sampling and reward modeling, optimizing for high-quality text rendering while maintaining overall visual coherence.
Experiment
- Conducted training using PyTorch with Hybrid Sharding Data Parallel (HSDP), gradient checkpointing, activation offloading, Flash Attention, and regional compilation, enabling efficient training of large models with bfloat16 mixed precision and FP32 master weights.
- Evaluated Ovis-Image on text rendering and general text-to-image generation using multiple benchmarks: CVTG-2K, LongText-Bench, DPG-Bench, GenEval, and OneIG-Bench.
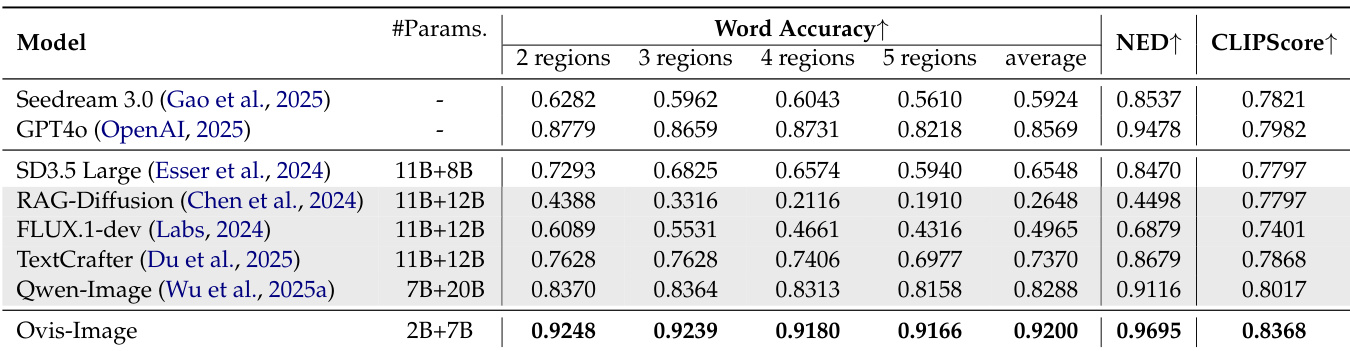
- On CVTG-2K, achieved the highest word accuracy, NED, and CLIPScore, demonstrating superior text rendering capability in English.
- On LongText-Bench, outperformed larger models in Chinese text rendering and matched closed-source models in long English text generation, highlighting strong long-text generation ability.
- On DPG-Bench, delivered robust prompt adherence across dense prompts, matching or exceeding larger open-source and closed-source models.
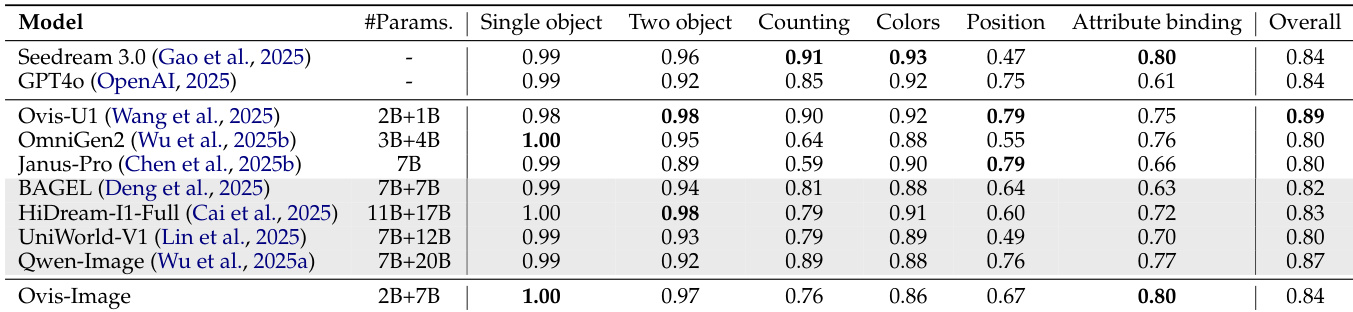
- On GenEval, showed competitive performance in object-centric generation with compositional prompts, indicating strong controllable generation.
- On OneIG-Bench, achieved exceptional bilingual performance, particularly excelling in text-related dimensions across both English and Chinese benchmarks.
- On computational efficiency, Ovis-Image achieved significantly lower GPU memory usage and faster inference time compared to larger baselines, demonstrating superior resource efficiency.
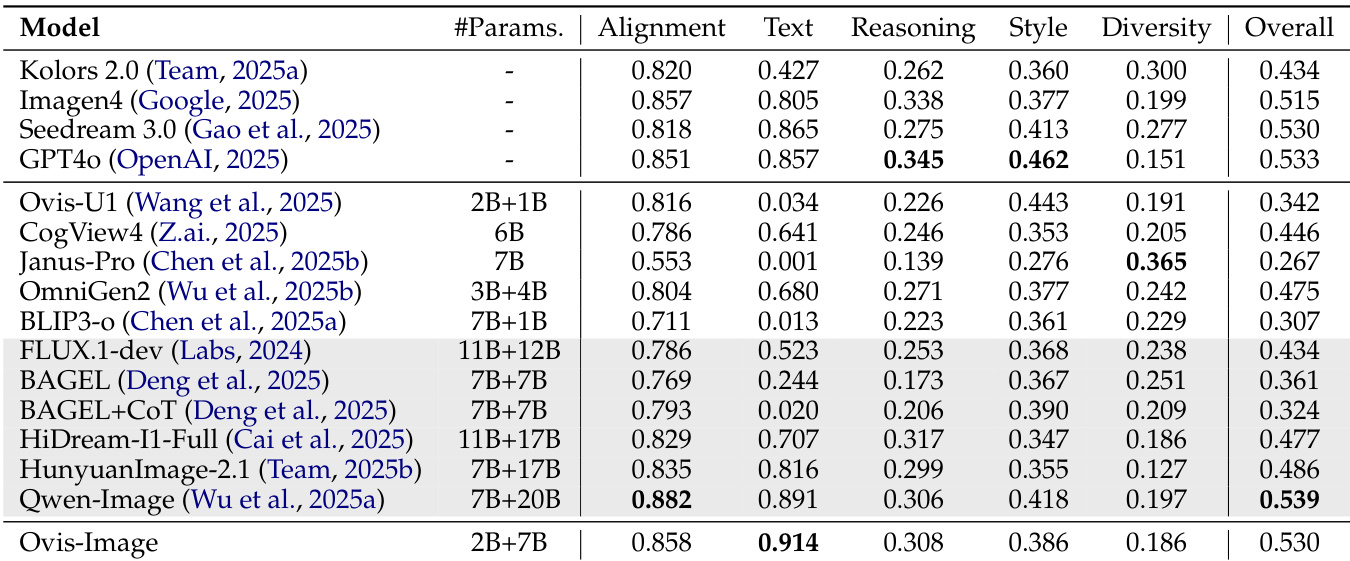
Results show that Ovis-Image achieves the highest overall score of 0.521, outperforming all other models across multiple evaluation dimensions including alignment, text rendering, and diversity. Despite having a smaller parameter count than several baselines, Ovis-Image demonstrates superior performance in text-related tasks, particularly in text rendering and bilingual generation, while maintaining a more efficient computational footprint.
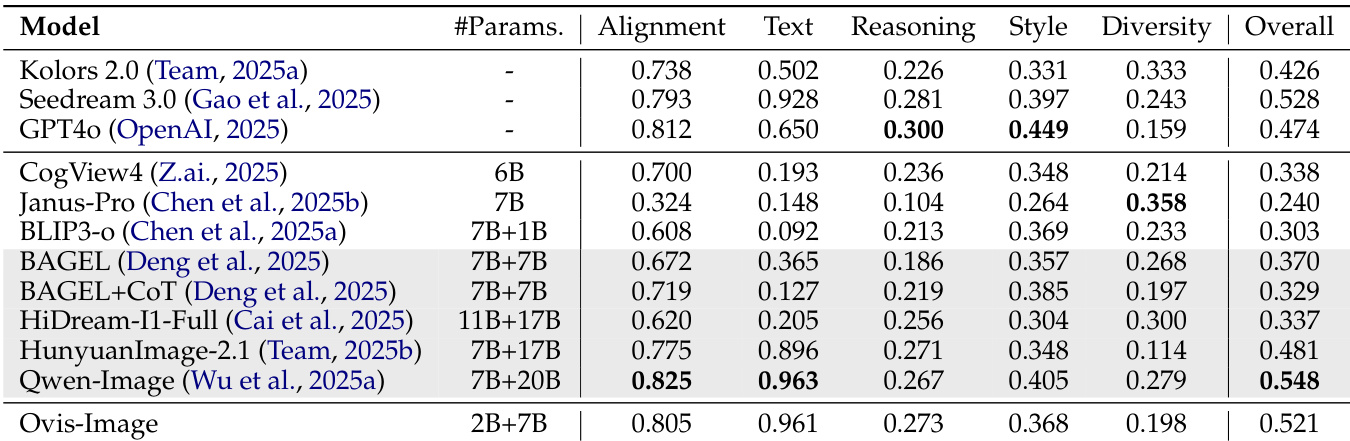
The authors use a modular architecture for Ovis-Image, with the total model size amounting to 10.02 billion parameters, composed of 7.37 billion from MMDiT, 2.57 billion from the Text Encoder, and 0.08 billion from the VAE. The Text Encoder is pre-trained on AIDC-AI/Ovis2.5-2B, while the VAE is pre-trained on black-forest-labs/FLUX.1-schnell, indicating a design focused on parameter efficiency and modular pre-training.
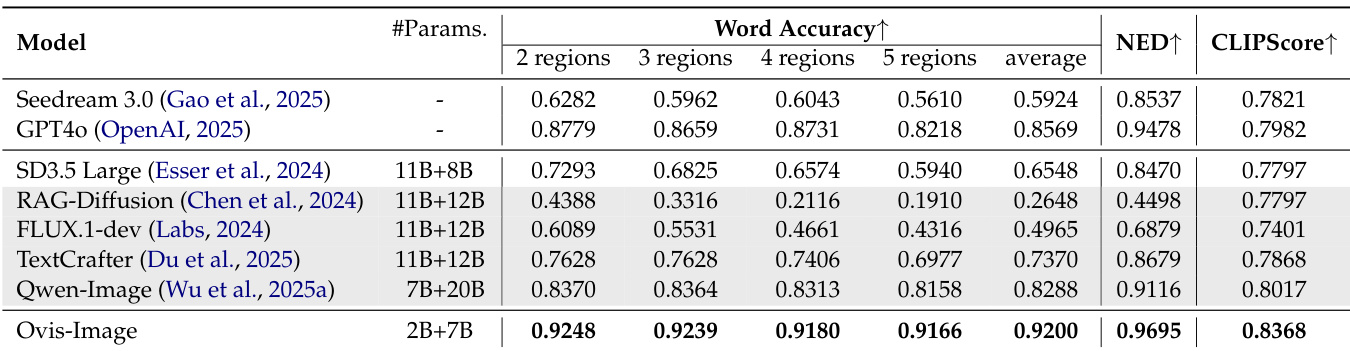
Results show that Ovis-Image achieves the highest word accuracy across all regions on the CVTG-2K benchmark, with an average score of 0.9200, outperforming all compared models. It also attains the best NED and CLIPScore, confirming its superior text rendering capability.
Results show that Ovis-Image achieves competitive performance across multiple text-to-image benchmarks, particularly excelling in single object generation with a score of 1.00, while maintaining strong overall performance despite its smaller parameter size. The model demonstrates superior efficiency in inference time and GPU memory usage compared to larger baselines, highlighting its effectiveness in resource-constrained environments.
Results show that Ovis-Image achieves the highest text rendering performance with a score of 0.914, outperforming all other models in the text dimension while maintaining strong overall generation quality. The model also demonstrates superior efficiency, requiring significantly less GPU memory and inference time compared to larger baselines, making it a practical solution for resource-constrained environments.