Command Palette
Search for a command to run...
WenetSpeech-Chuan 川渝方言语音数据集
WenetSpeech-Chuan 是由西北工业大学联合希尔贝壳、中国电信人工智能研究院等机构于 2025 年发布的一个规模庞大的川渝方言语音数据集,相关论文成果为「WenetSpeech-Chuan: A Large-Scale Sichuanese Corpus with Rich Annotation for Dialectal Speech Processing」。
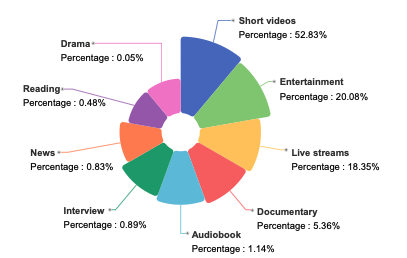
该数据集共包含 10,013 小时的真实川渝方言语音,其中包括 3,714 小时的强标签数据和 6,299 小时的弱标签数据。数据覆盖 9 大真实场景领域,其中短视频占 52.83%,其余还包括娱乐、直播、有声书、纪录片、采访、新闻、阅读和剧集,呈现出高度多样且贴近现实的语音分布。所有语音均附带丰富的标注信息,如文本内容、置信度、音质评分、说话人的性别与年龄,以及情绪标签等。
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.
AI Co-coding
Ready-to-use GPUs
Best Pricing
HyperAI Newsletters
订阅我们的最新资讯
我们会在北京时间 每周一的上午九点 向您的邮箱投递本周内的最新更新
邮件发送服务由 MailChimp 提供