Command Palette
Search for a command to run...
MEM1:学习协同记忆与推理以实现高效长时程Agent
MEM1:学习协同记忆与推理以实现高效长时程Agent
Zijian Zhou Ao Qu Zhaoxuan Wu Sunghwan Kim Alok Prakash Daniela Rus Jinhua Zhao Bryan Kian Hsiang Low Paul Pu Liang
Abstract
现代语言智能体必须在长时程、多轮交互中运行,其间需检索外部信息、适应环境观测,并回答相互依赖的多个问题。然而,目前大多数大语言模型(LLM)系统依赖于全上下文提示(full-context prompting),即无差别地拼接所有历史交互轮次,无论其相关性如何。这导致内存占用无限制增长、计算成本上升,并在输入长度超出训练分布时显著降低推理性能。为此,我们提出 MEM1——一种端到端的强化学习框架,使智能体在长时程多轮任务中能够以恒定内存运行。在每一轮交互中,MEM1 更新一个紧凑的共享内部状态,该状态同时支持记忆整合与推理能力。该状态在融合先前记忆与环境新观测信息的同时,有策略地丢弃无关或冗余内容。为支持在更真实、更组合化的场景中进行训练,我们提出一种简单但高效且可扩展的方法:通过组合现有数据集,构建任意复杂度的任务序列,从而生成多轮交互环境。在三个不同领域(包括内部检索问答、开放域网络问答,以及多轮网络购物)的实验表明,在一个包含16个目标的多跳问答任务中,MEM1-7B 相较于 Qwen2.5-14B-Instruct,性能提升达3.5倍,内存使用量降低3.7倍,并展现出超越训练时长范围的泛化能力。结果表明,以推理为导向的记忆整合机制,为训练长时程交互式智能体提供了一种可扩展的替代方案,在兼顾效率与性能方面展现出巨大潜力。
一句话总结
来自新加坡-麻省理工学院研究与技术联盟、新加坡国立大学、麻省理工学院和延世大学的研究人员提出MEM1,一种强化学习框架,使语言代理在长时间多轮交互中保持恒定内存,通过动态将相关信息整合到紧凑的内部状态中。与全上下文提示不同,MEM1有策略地丢弃冗余信息,提升了推理效率和性能——在复杂问答任务上,相比Qwen2.5-14B-Instruct,结果提升3.5倍,内存使用降低3.7倍——同时在训练范围之外也具备泛化能力。
主要贡献
- 现代语言代理在长时程、多轮交互中面临重大挑战,源于全上下文提示导致的无界内存增长,这增加了计算成本,并在长输入情况下降低推理性能。
- MEM1引入端到端强化学习框架,通过维护一个紧凑且共享的内部状态,实现恒定内存使用,该状态同时支持推理与记忆整合,动态融合相关信息并丢弃冗余。
- 在三个领域进行的实验表明,MEM1-7B在16目标多跳问答任务上,性能比Qwen2.5-14B-Instruct高出3.5倍,内存使用降低3.7倍,同时在训练范围之外实现泛化,并通过一种新颖的数据集组合方法实现可扩展性,适用于真实多轮环境。
引言
现代语言代理日益需要处理长时程、多轮交互任务——如科研、网页导航和复杂决策——在此类任务中,代理必须持续检索信息、适应新观察,并对相互依赖的查询进行推理。然而,现有系统通常依赖全上下文提示,将所有先前交互内容拼接在一起,导致内存无界增长、计算成本上升,且在上下文长度超过训练限制时推理性能显著下降。这些方法还存在上下文过载效率低下、缺乏端到端记忆管理优化的问题。本文作者提出MEM1,一种端到端强化学习框架,使代理能够在任意长任务中保持恒定内存使用,通过学习将推理与记忆整合到一个紧凑的共享内部状态中。该状态在整合相关信息的同时丢弃冗余,无需保留先前上下文。为支持可扩展训练,作者提出一种任务增强方法,将单目标数据集组合为复杂、多跳序列。在检索问答、开放域网页问答和多轮购物任务上的实验表明,MEM1-7B在16目标任务上性能比Qwen2.5-14B-Instruct高出3.5倍,内存使用降低3.7倍,同时在训练范围之外实现泛化。该工作表明,以推理驱动的记忆整合为传统长上下文建模提供了一种可扩展、高效的替代方案。
数据集
- 长时程问答数据集通过增强来自[24]的多跳问答数据集构建,该数据集结合了HotpotQA [59]和Natural Question [26]的数据,形成一个双目标复合任务。
- 数据集中的每个实例包含一个复合查询,交错排列原始语料库中的多个子问题,要求代理执行多次搜索与推理步骤以回答所有组成部分。
- 训练与测试划分遵循原始论文,测试数据来自分布外样本,用于评估泛化能力。
- 在网页导航任务中,使用WebShop环境[60],该环境在训练期间提供特定于环境的奖励,并支持在交互式真实场景中评估代理行为。
- 作者使用混合训练数据:针对问答任务使用增强的多目标问答数据集,针对网页导航任务使用WebShop数据,每项任务均通过强化学习独立训练。
- 训练过程中,问答任务使用精确匹配(EM)和F1分数进行评估,WebShop任务使用最终环境奖励。效率通过峰值token使用量、平均依赖长度和平均推理时间衡量。
- 为支持长时程交互,代理的上下文在每次搜索查询或答案生成后被程序化截断,以保持内存效率。
- 每个标签前添加元信息提示[HINT: YOU HAVE {turns_left} TURNS LEFT],以指导终止决策,1–4目标任务最多6轮,更复杂任务最多20轮。
- 在检索任务中,系统使用Faiss-GPU与E5 Base模型在Wikipedia 2018数据集上进行本地RAG,每查询检索3段文本。在线网页搜索使用Serper API获取前10条Google搜索结果(标题、摘要、URL),无需完整页面获取。
方法
作者利用强化学习(RL)框架训练MEM1,一种旨在长时程推理任务中保持恒定内存使用的代理。其核心架构围绕一种动态上下文管理机制,使代理能够在丢弃无关历史信息的同时迭代优化其内部状态。在每个推理步骤t,代理生成一个内部状态ISt,该状态封装了过去信息与推理的综合摘要。此内部状态用于决定下一步动作:向外部环境(如搜索引擎或知识库)发出查询queryt,或直接给出答案answert。若发出查询,则环境提供反馈infot,该反馈随后被纳入代理的上下文。代理随后将元组(ISt,queryt,infot)整合为新的内部状态ISt+1,作为下一步推理的基础。此过程确保仅保留最相关信息,因为所有先前上下文元素在每轮后均被修剪。该框架设计为保持有界内存使用,代理在任何时刻最多保留两个内部状态、两个查询和一条环境反馈。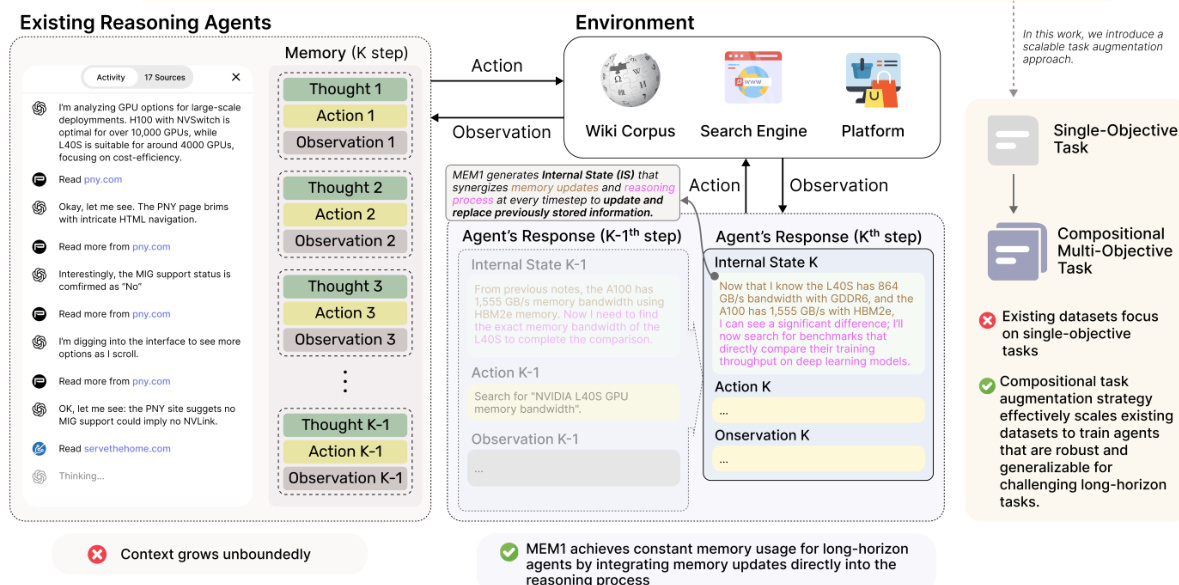
训练过程采用强化学习流水线,代理因成功完成需要与环境多次交互的任务而获得奖励。奖励信号设计为迫使代理依赖其内部记忆,随时间累积并整合有用信息。这通过在每轮后强制修剪上下文实现,防止代理访问完整历史记录。因此,代理学习到有效的记忆整合成为其推理策略的必要组成部分。RL框架在整体系统图中展示,显示了代理内部状态、环境与奖励分配机制之间的交互。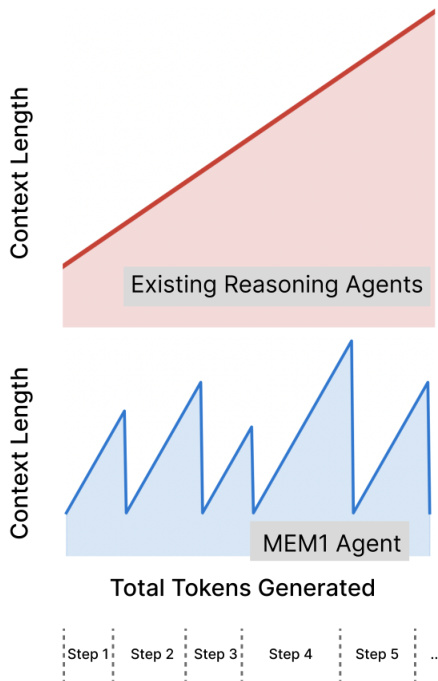
为应对策略优化过程中动态上下文更新带来的挑战,作者引入一种掩码轨迹方法。该方法通过拼接多个交互轮次,重构出逻辑连贯的完整轨迹,其中每轮表示为元组(ISt,queryt,infot),t∈[1,T−1],最后一轮输出答案。此统一轨迹允许应用标准策略优化算法,尽管代理上下文演化具有非线性特征。该方法的关键组件是在目标计算阶段使用二维注意力掩码。该掩码限制每个token的注意力仅作用于生成该token时存在于内存中的token,确保在内存受限环境下正确计算策略梯度。注意力掩码在前向传播中应用于计算动作对数概率(用于演员模型)和状态价值估计(用于评论家模型)。在策略更新阶段,对完整轨迹应用额外的一维注意力掩码,以确保梯度更新仅限于模型自身生成的token。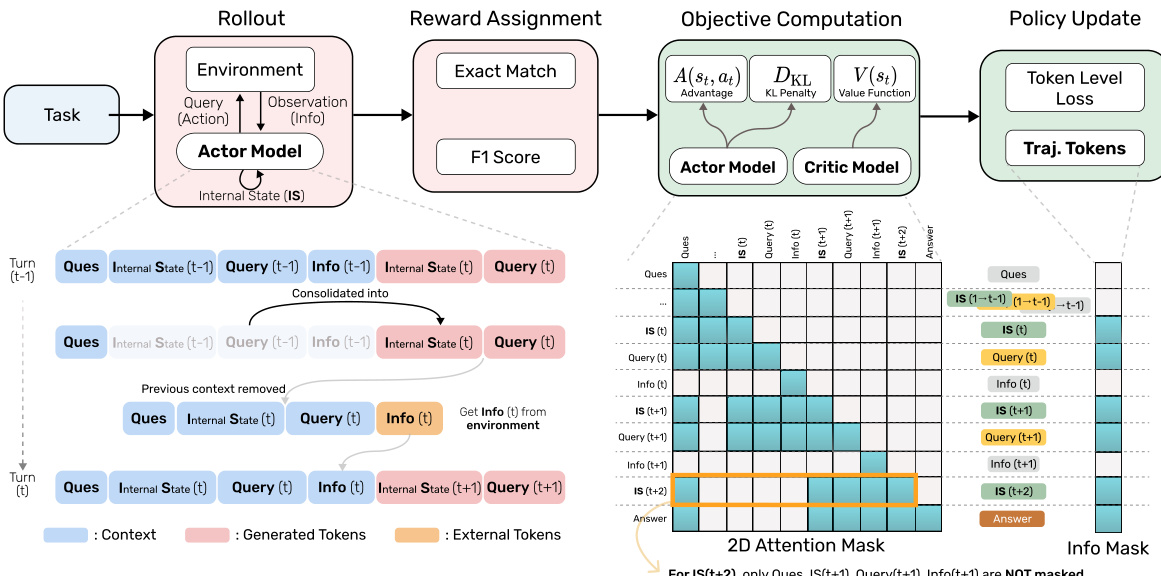
MEM1的rollout过程在算法1中详细说明,概述了代理的逐步执行流程。算法从初始任务提示开始,依次进行多轮交互,每轮涉及生成响应token序列。代理持续生成token,直到产生查询或答案。若检测到查询,则代理提取搜索查询,从环境中获取反馈,并将信息附加到上下文中。该过程持续至达到最大轮数或代理生成最终答案。算法确保每轮后上下文重置,维持恒定内存特性。
实验
- MEM1在双目标问答任务上通过强化学习训练,在多目标多跳问答和WebShop导航任务上表现出色,性能优于7B基线模型,甚至在高目标设置下超越Qwen2.5-14B-Instruct。
- 在16目标问答任务上,MEM1的峰值token使用量仅为Qwen2.5-14B-Instruct的27.1%,推理时间仅为29.3%,同时保持高准确率(EM和F1分数)。
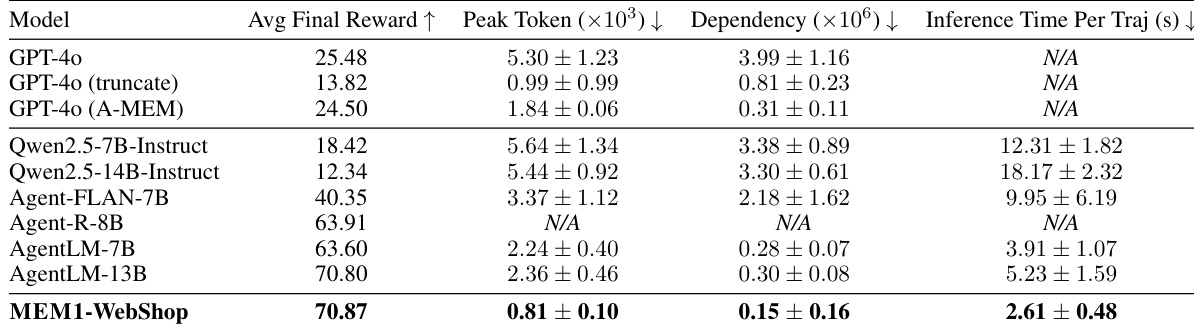
- 在WebShop导航任务中,MEM1优于Agent-Flan、Agent-R和AgentLM,峰值token使用量提升2.8倍,依赖长度缩短1.9倍,推理时间加快1.5倍,甚至超越AgentLM-13B。
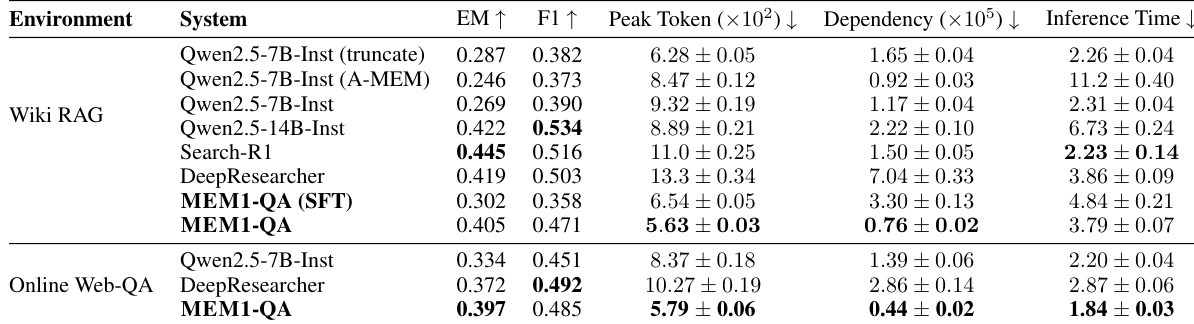
- 在单目标维基百科问答任务上,MEM1达到最高EM分数,F1分数与Qwen2.5-14B-Instruct相当,且峰值token使用量、依赖长度和推理时间显著更低。
- MEM1在在线网页问答任务上展现出强大的零样本迁移能力,无需重新训练即可保持高效率与竞争力准确率。
- 出现的涌现行为包括并发多问题管理、动态焦点切换、记忆整合、查询优化、自我验证和子目标分解,支持高效长时程交互。
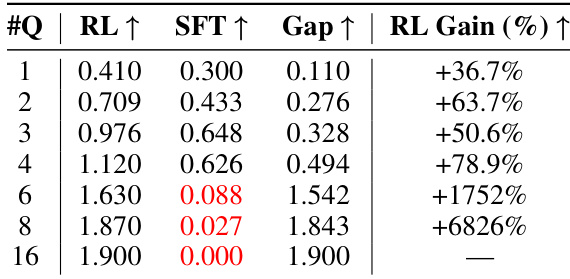
- 强化学习训练始终优于监督微调(SFT),SFT在超过六个目标的任务上崩溃,而RL训练的MEM1保持鲁棒性与可扩展性。
- 添加格式奖励可加速收敛,但会降低最终性能,表明基于结果的奖励更有利于有效推理与记忆利用。
作者使用一组全面的指标,将MEM1与多种基线模型(包括GPT-4o和其他代理模型)在多轮任务中进行对比评估。结果表明,MEM1在保持显著更低的峰值token使用量、依赖长度和推理时间的同时,实现了最高的平均最终奖励,展现出卓越的效率与性能。
结果表明,MEM1-QA在2、8和16目标任务上均优于所有其他模型的精确匹配和F1分数,同时保持显著更低的峰值token使用量和推理时间。该模型展现出卓越的可扩展性,随着目标数量增加,其内存使用几乎保持恒定,在长时程任务上的效率与性能均超越Qwen2.5-14B-Instruct等更大模型。

结果表明,MEM1-QA在Wiki RAG和在线网页问答任务上均达到具有竞争力的准确率,EM和F1分数与甚至超过Qwen2.5-14B-Instruct等更大模型,同时显著降低峰值token使用量、依赖长度和推理时间。该模型在内存管理方面展现出显著效率提升,即使在任务复杂度增加时,峰值token数量也几乎保持恒定。
结果表明,RL训练的MEM1代理在所有多轮任务上均优于SFT训练模型,且随着问题数量增加,性能差距进一步扩大。SFT模型在超过六个问题的任务上崩溃,而RL模型保持强劲表现,在六问题任务上相比SFT提升1752%,在十六问题任务上提升6826%。