Command Palette
Search for a command to run...
视频现实性测试:AI生成的ASMR视频能否欺骗视觉语言模型(VLMs)与人类?
视频现实性测试:AI生成的ASMR视频能否欺骗视觉语言模型(VLMs)与人类?
Jiaqi Wang Weijia Wu Yi Zhan Rui Zhao Ming Hu James Cheng Wei Liu Philip Torr Kevin Qinghong Lin
Abstract
近年来,视频生成技术取得了显著进展,生成的内容日益逼真,往往与真实视频难以区分,这使得AI生成视频的检测成为一项日益紧迫的社会性挑战。以往的AIGC(AI生成内容)检测基准大多仅评估无音频的视频,关注广泛的叙事领域,且仅聚焦于分类任务。然而,当前最先进的视频生成模型是否能够生成在音画高度耦合下具有沉浸感、能有效欺骗人类与视觉语言模型(VLMs)的视频,仍不明确。为此,我们提出了Video Reality Test——一个基于ASMR(自主感觉经络反应)内容构建的视频基准测试套件,旨在评估在强音画耦合条件下的感知真实感。该基准具有以下核心特征:(i) 沉浸式ASMR音视频源。基于精心筛选的真实ASMR视频数据,该基准聚焦于细粒度的动作-物体交互,涵盖多样化的物体、动作与背景场景,以增强真实感与复杂性。(ii) 同行评审式评估机制。采用对抗性“创作者-评审者”协议:视频生成模型作为“创作者”,目标是生成足以欺骗评审者的视频;而VLMs则作为“评审者”,任务是识别视频的虚假性。实验结果表明:- 当前表现最优的生成模型Veo3.1-Fast甚至能欺骗多数VLMs:最强的评审模型(Gemini 2.5-Pro)的识别准确率仅为56%(随机猜测为50%),远低于人类专家水平(81.25%)。- 加入音频信息有助于提升真假视频的辨别能力,但诸如水印等表面线索仍可能显著误导模型判断。上述发现揭示了当前视频生成技术在真实感方面的边界,同时暴露了现有VLMs在感知保真度与音画一致性方面的显著局限性。相关代码已开源,地址为:https://github.com/video-reality-test/video-reality-test。
一句话总结
来自香港中文大学、新加坡国立大学、Video Rebirth 和牛津大学的研究人员提出基于 ASMR 的 Video Reality Test 基准测试,通过对抗性创作者-评审协议评估 AI 生成视频的音视频真实性;实验表明 Veo3.1-Fast 等生成器可欺骗视频语言模型(Gemini 2.5-Pro 准确率仅 56%),而人类判断准确率达 81.25%,凸显音频在 AIGC 检测中的关键作用及水印漏洞问题。
核心贡献
- 提出 Video Reality Test,首个专为紧密音视频耦合场景设计的 AI 生成视频检测基准,填补了先前研究忽略音频、聚焦非欺骗性分类任务(未测试视频能否欺骗人类或 VLM)的空白。该基准包含 149 条精选真实 ASMR 视频,覆盖物体、动作和背景多样性,并配对 AI 生成视频以进行严格的真假评估。
- 设计新型 同行评审评估框架:视频生成模型作为对抗性"创作者"试图欺骗"评审者"(VLM 或人类),通过双向性能指标建立竞争性评估场域,联合衡量生成与检测能力。该协议揭示了创作者与评审者间的动态博弈,明确哪些模型在欺骗或检测方面表现优异。
- 实验证明 Veo3.1-Fast 等顶尖生成器对现有检测系统构成严峻挑战:最强 VLM 评审者(Gemini 2.5-Pro)准确率仅 56%(远低于人类专家 81.25%);引入音频可将判别准确率提升约 5 个百分点,但水印等表面线索仍会误导模型。结果量化了现代视频生成的真实边界,并暴露 VLM 在感知保真度方面的关键缺陷。
引言
AI 生成视频的快速普及通过制造复杂虚假信息威胁信息完整性。先前检测方法局限于面部伪造或空间伪影(如 FaceForensics++ 基准),难以应对具有 unprecedented 时间连贯性与减少视觉不一致性的扩散模型。现有方法亦未能全面评估音视频真实性,或建模生成器与检测器间的对抗动态。作者提出 Video Reality Test 统一基准,将检测建模为视频生成器("创作者")与多模态检测器("评审者")间的竞争性同行评审过程,特别采用高保真 ASMR 内容跨音视频维度评估真实与合成视频。该框架通过单一对抗生态系统实现生成质量与检测鲁棒性的可扩展评估,有效弥补了先前孤立评测的局限。
数据集
- 采用 Video Reality Test 基准,基于 149 条精选真实 ASMR 视频构建(源自 YouTube,从 1,400 条候选视频中筛选,以 >90 万播放量作为人类沉浸度代理指标)。
- 子集细节:
- 简单集:49 条视频;短时长(3–5 秒)、单步骤动作(如切食物)、极简背景(如暗色室内)、低物体多样性。
- 困难集:100 条视频;长时长(20+ 秒)、多步骤动作(如挤压/剥皮)、多样化场景(室内外)、丰富物体类型(固体如肥皂/液体如油漆)。
- 伪造视频由 K 个视频模型按实验 动态生成,总数据集规模为 149×(1+K)。
- 论文使用方式:
- 真实视频作为基线;伪造视频按需使用 首帧 或 Gemini-2.5-Pro 文本描述 生成。
- 数据训练"同行评审"游戏:VLM("评审者")判别视频真假,生成器("创作者")力求最小化检测率。
- 评估指标包含评审者准确率(真实视频目标值 1,伪造视频目标值 0)及创作者欺骗率。
- 处理细节:
- 裁剪:原始视频按场景转换分割(基于帧颜色直方图/Bhattacharyya 距离 >0.5),通过灰度列分析移除背景/水印。
- 元数据:Gemini-2.5-Pro 基于 8 帧均匀采样生成沉浸式文本描述,避免结构化标记。
- 筛选:人工验证确保单主题片段;Qwen3-embedding-4B 将描述聚类为 8 类,每类精选 12–13 条高质量样本以平衡表征(总计 100 条)。
实验
- 在 Video Reality Test ASMR 基准上评估 VLM:顶尖模型 Gemini-3-Pro 在 7 个 VLM 中准确率达 76.27%,显著低于人类表现(89.11%),验证当前 VLM 真假检测能力有限。
- 通过欺骗率测试 VGM:Veo3.1-Fast 生成的视频仅 12.54% 被识别为伪造,超越 Sora2 及开源模型,展现最强欺骗能力。
- 分析音频影响:引入音频使 VLM 检测准确率平均提升 ∼5 个百分点,因不匹配音频(如 Sora2 在 ASMR 中的人声)提供判别线索。
- 评估水印影响:移除 Sora2 水印后,GPT-5 和 Gemini-2.5-Pro 检测准确率从 95.43% 降至 52.4%,暴露模型依赖表面捷径而非真实感知分析。
- 识别 VLM 偏差:模型将 71% 视频分类为真实(含 33% 伪造视频),证实系统性保守偏差——无论来源均倾向认证内容。
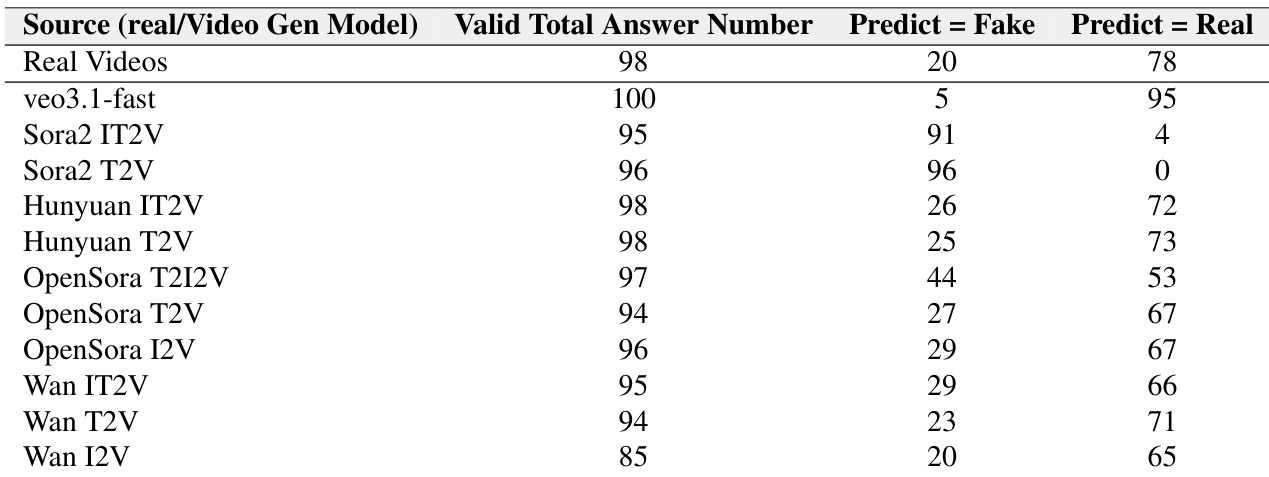
作者通过同行评审评估视频生成模型欺骗视频理解模型的能力,结果显示 Veo3.1-fast 生成的视频欺骗性最强(96 条中仅 19 条被正确识别为伪造)。Sora2 和 StepVideo-t2v 生成的视频更易被检测(误判数分别为 63 和 84),表明其真实性较弱。所有模型中,VLM 均强烈偏向将视频分类为真实:95 条真实视频中 88 条被正确识别,而生成视频常被误判为真实。
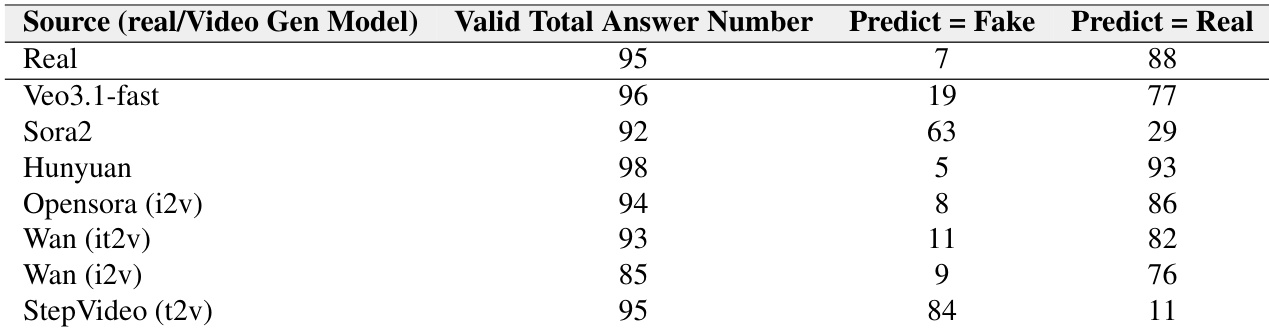
作者通过此表格报告视频理解模型将真实与生成 ASMR 视频误判为真实的频率,揭示模型强烈偏向标记视频为真实。Veo3.1-fast 生成的视频最常被误认为真实(100 条中 83 条),而 StepVideo T2V 视频最易被正确识别为伪造(100 条中 84 条)。所有模型中,真实视频被预测为真实的概率高达 94%(100 条中 94 条),证实模型保守倾向——即使面对合成内容也默认"真实"。
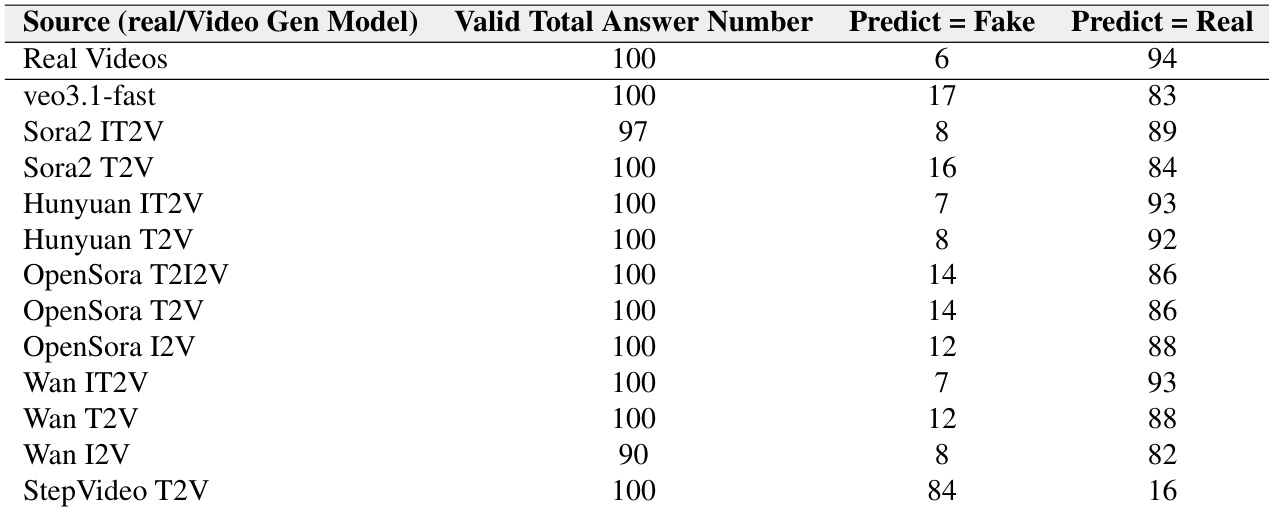
作者通过同行评审测试视频生成模型欺骗视频理解模型的能力,结果显示 Veo3.1-fast 生成的视频欺骗性最强(89% 被误判为真实)。Sora2 和 Hunyuan 模型亦生成高真实性内容(检测率低于 15%),而 StepVideo T2V 最不具说服力(92% 被正确识别为伪造)。所有模型中,视频理解系统均强烈偏向将视频标记为真实,即使内容为 AI 生成。
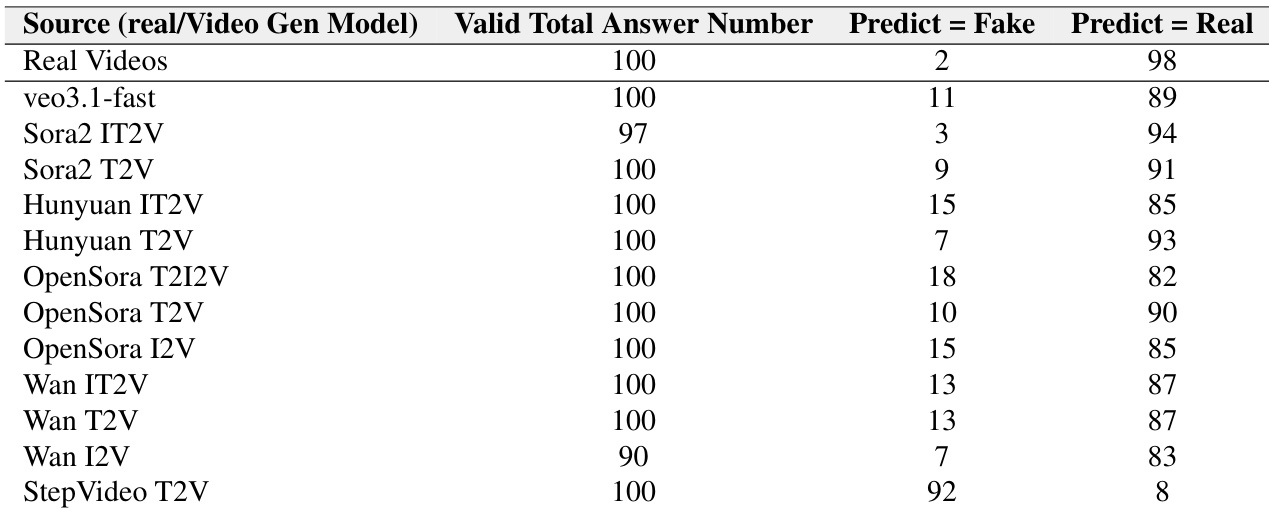
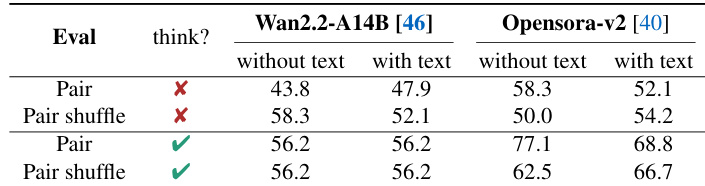
作者在不同提示与推理设置下评估视频理解模型,发现要求模型"思考后再回答"仅对强模型有效,弱模型收益甚微。结果还表明基于偏好的评估(对比真实与伪造配对)比单视频判别更简单,无论伪造视频是否源自同一真实样本,模型在配对场景中均表现更优。
作者通过此表格展示不同视频生成模型欺骗视频理解模型的频率:Veo3.1-fast 生成的视频欺骗性最强(仅 5% 被正确识别为伪造)。Sora2 模型表现出极端偏差——Sora2 T2V 被 100% 误判为真实,而 Sora2 IT2V 被 91% 识别为伪造,表明模型配置显著影响可检测性。所有模型中,VLM 始终倾向于预测视频为真实而非伪造,证实其对真实性的强烈分类偏差。