Command Palette
Search for a command to run...
NHS基层医疗中LLM药物安全审查的现实世界评估
NHS基层医疗中LLM药物安全审查的现实世界评估
Oliver Normand Esther Borsi Mitch Fruin Lauren E Walker Jamie Heagerty Chris C. Holmes Anthony J Avery Iain E Buchan Harry Coppock
Abstract
大型语言模型(LLMs)在多项医学基准测试中表现达到甚至超过临床医生水平,然而极少有模型在真实临床数据上进行评估,也缺乏对超出表面指标的深入分析。据我们所知,本文首次基于英国国家医疗服务体系(NHS)基层医疗的真实数据,对一个基于LLM的药物安全审查系统进行了系统性评估,并对不同临床复杂度下关键失败行为进行了详尽刻画。在一项回顾性研究中,我们利用覆盖英格兰柴郡与默西赛德地区2,125,549名成人的大规模电子健康记录(EHR)数据集,有策略地抽样以涵盖广泛的临床复杂度和药物安全风险,最终在数据质量剔除后获得277名患者。由资深临床专家对系统识别出的问题及建议干预措施进行独立评审与分级。我们的主LLM系统在识别临床问题存在性方面表现出色(敏感性100% [95%置信区间 98.2–100],特异性83.1% [95%置信区间 72.7–90.1]),但在所有患者中仅正确识别出全部问题与干预措施的比例为46.9% [95%置信区间 41.1–52.8]。失败分析表明,在该场景下,主要的失败机制并非药物知识缺失,而是情境推理能力不足,共识别出五类核心模式:在不确定性情境中表现出过度自信、机械套用标准指南而未结合患者具体背景、对实际医疗实践流程理解错误、事实性错误,以及对临床流程的“盲视”(process blindness)。这些失败模式在不同临床复杂度和人口学分层中均持续存在,并在多种先进模型及其配置中广泛出现。本文提供了45个详尽的案例研究(vignettes),全面覆盖了所有识别出的失败情形。本研究揭示了在将基于LLM的临床人工智能系统安全投入实际应用前,必须解决的若干关键缺陷。同时,也呼吁开展更大规模、前瞻性评估,并对LLM在真实临床环境中的行为进行更深入的研究。
一句话总结
来自i.AI/DSIT、利物浦大学等机构的研究人员首次在真实NHS环境中评估了基于大语言模型(LLM)的用药安全系统,通过对277例复杂患者案例的分析发现:尽管系统敏感性达100%,但情境推理缺陷(尤其是过度自信与指南僵化)成为主要限制因素,揭示了临床部署前必须解决的关键安全漏洞。
核心贡献
- 本研究填补了在真实临床数据上评估大语言模型(LLMs)的关键空白。先前研究多依赖合成基准测试,尽管LLMs在受控环境中能达到临床医生水平。本文首次基于真实NHS初级医疗记录评估LLM用药安全审查系统,并超越表面指标进行深度失效分析。
- 研究者构建了严格的分层评估框架,应用于包含2,125,549名成年人的全人群电子健康记录(EHR)数据集,通过策略性抽样选取277名高复杂度患者进行临床专家评审,以刻画真实临床场景中的失效模式。分析表明:情境推理缺陷(而非医学知识缺失)是主要错误来源,识别出五类持续性问题:不确定性下的过度自信、指南僵化应用、医疗服务体系误解、事实性错误及诊疗流程盲区。
- 回顾性研究证据显示:主LLM系统虽达到100%敏感性,但仅46.9%的患者能被准确识别全部问题并提出有效干预。失效模式在患者复杂度、人口统计特征及多种最先进模型中保持一致。本研究提供45个详细临床案例记录,证明当前LLM无法可靠处理安全部署所需的精细临床推理。
引言
用药安全审查在初级医疗中至关重要,因处方错误导致的可预防伤害每年使NHS损失高达16亿英镑,并造成8%的住院率。尽管大语言模型(LLMs)在医学基准测试中展现出媲美临床医生的潜力,但先前评估存在显著缺陷:多数研究依赖合成数据或考试式问题而非真实患者记录;自动评分常遗漏幻觉等临床显著错误;复杂医疗流程中的失效模式尚未明确刻画。本研究通过在真实NHS初级医疗记录上评估LLM,引入三层分层框架解构失效原因。通过对148名患者的分析证明:情境推理缺陷(如误判时间相关性或患者特异性因素)数量是事实错误的6倍,揭示了理论模型能力与安全临床部署之间的关键差距。
数据集
研究采用NHS柴郡和默西塞德可信研究环境(GraphNet Ltd.)的电子健康记录,覆盖2,125,549名18岁以上成人的结构化SNOMED CT与dm+d编码数据。关键细节包括:
- 主数据集:含GP事件、用药记录、住院记录及临床观察的纵向患者档案(无自由文本记录)。患者平均1,010次GP事件;时间跨度1976–2025年。人口特征显示更高剥夺指数(26.6%处于英格兰最贫困十分位,最低贫困组仅7.7%)。
- 评估子集:从20万患者测试集中抽样300人,排除23例数据问题后保留277例。抽样包含:
- 100名用药安全指标阳性患者(分层覆盖10项指标)
- 100名经年龄、性别、处方及近期GP事件匹配的指标阴性患者
- 指标阴性人群中50名系统阳性与50名系统阴性案例
研究者将原始parquet文件处理为结构化Pydantic患者档案,转换为按时间排序的Markdown格式进行分析,包含人口统计、诊断、现用/既往用药、检验结果及临床观察。277例患者的临床反馈经gpt-oss-120b整合为金标准(经验证的临床问题与干预方案)。数据治理遵循NHS柴郡与默西塞德审批,匿名档案严格按可信研究环境协议分析(2025年6–11月)。
方法
研究采用结构化三阶段流程评估用药安全系统,整合自动分析与临床验证。流程始于从电子健康记录(EHR)提取的纵向患者档案,包含人口统计、QOF注册表、临床事件及现用药物。档案经标准化患者提示词输入系统,要求系统标记安全问题并提出干预方案。系统输出包括摘要、带证据支持的临床问题列表及必要时的具体干预计划。
参见框架示意图,展示从原始EHR数据到系统分析再到临床评审的端到端工作流。临床医生手动评估系统输出,验证标记问题的存在性/正确性及干预方案的适当性。此人工评审作为后续自动评分的金标准。

评估采用三层分层框架:1级评估系统在存在问题时是否正确识别;2级(基于1级成功)评估系统是否识别全部相关问题;3级(基于2级成功)判断所提干预是否直接解决安全问题。这种分层方法可精确诊断失效点。
为扩展多模型评估,研究者开发了自动评分器Sautomated,以临床评审案例为金标准。该评分器用LLM将临床反馈合成结构化问题与干预列表,再通过独立LLM裁判基于F1指标计算问题识别与干预适当性的匹配分数。真阴性(确认无问题)得1.0分;问题存在性分歧得0.0分。此机制支持模型间定量比较及性能差异分析(如按患者种族)。
系统输出需符合严格JSON模式,包含患者审查、临床问题(含问题描述、证据及intervention_required标志)、干预计划及干预概率字段。干预必须具体可行且直接解决问题(如"停用维拉帕米"),而非模糊建议。仅当问题存在重大、当前、循证风险且可通过具体行动解决时,intervention_required才置为true。
失效模式通过五类分类法系统归类,该分类基于148名患者中178例失效案例的临床评审。每例失效还按WHO患者安全伤害等级(从无伤害到死亡)评估潜在临床影响。
实验
- 在277名患者的真实NHS初级医疗数据上评估gpt-oss-120b LLM系统,二元干预检测敏感性达100% [95% CI 98.2–100],特异性83.1% [95% CI 72.7–90.1],但仅46.9% [95% CI 41.1–52.8]的输出能准确识别问题并提出完整干预。
- 失效分析显示86%错误源于情境推理(如过度自信、协议误用),仅14%为事实错误,且模式在患者复杂度与人口群体中保持一致。
- 性能随临床复杂度下降(用药数量r = -0.28, p < 0.001),多模型对比表明gpt-oss-120b-medium比小型/微调模型在临床评分中高5.6–70.3%。
- 锚定偏差分析显示临床共识准确率(95.7%)与模型自洽性上限(87.8%)存在7.9%差距;种族反事实测试表明白人、亚裔或黑人患者档案间无显著性能差异(p=0.976)。
研究者通过临床评审评估基于LLM的用药安全系统在真实NHS数据上的表现:系统虽以100%敏感性标记问题案例,但仅58.7%的案例能正确识别全部相关问题,且仅58.7%的标记案例提出完全适当的干预。结果表明系统性能随分层评估层级下降,仅46.9%患者获得完全正确输出,凸显问题检测与情境化解决方案之间的差距。
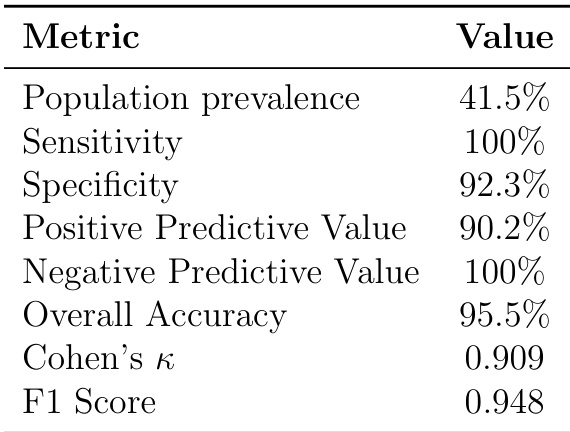
研究者采用分层抽样方法在真实NHS数据上评估基于LLM的用药安全系统,报告基于95名未筛选患者的群体级性能指标。结果显示系统敏感性100%、特异性92.3%、总体准确率95.5%、阴性预测值接近完美,表明真阴性检测能力强但实际部署中可能存在假阳性。
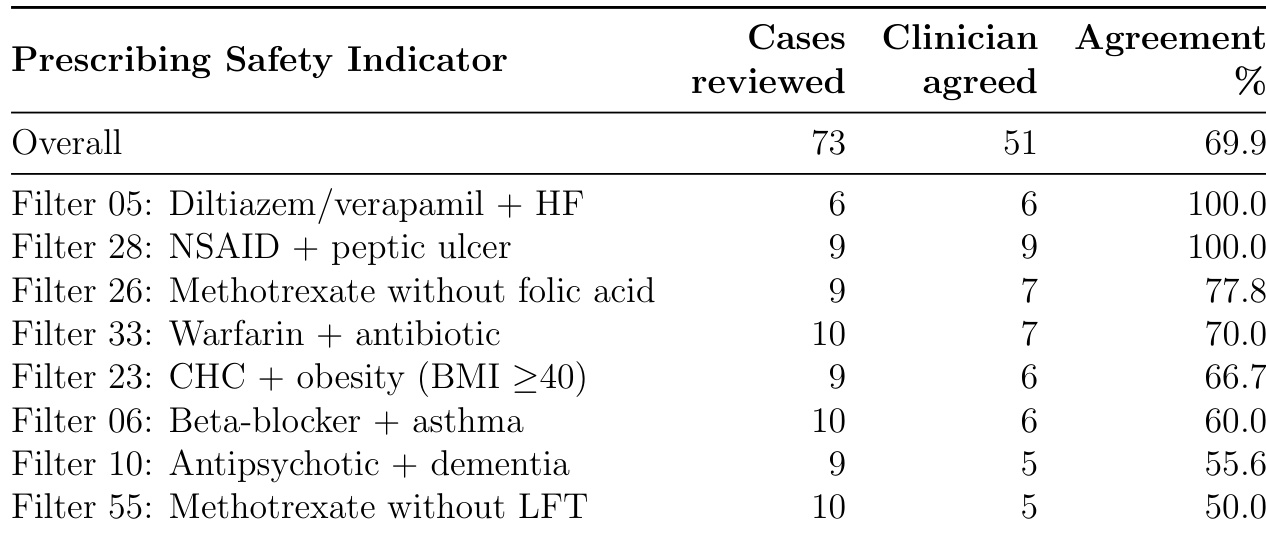
研究者评估73例中临床医生对自动化用药安全指标的共识,发现69.9%的标记问题被认为需干预。共识率因指标类型差异显著:心衰患者使用地尔硫卓/维拉帕米等绝对禁忌证达100%,而甲氨蝶呤未监测肝功能仅50%,表明确定性规则常需情境化临床判断。
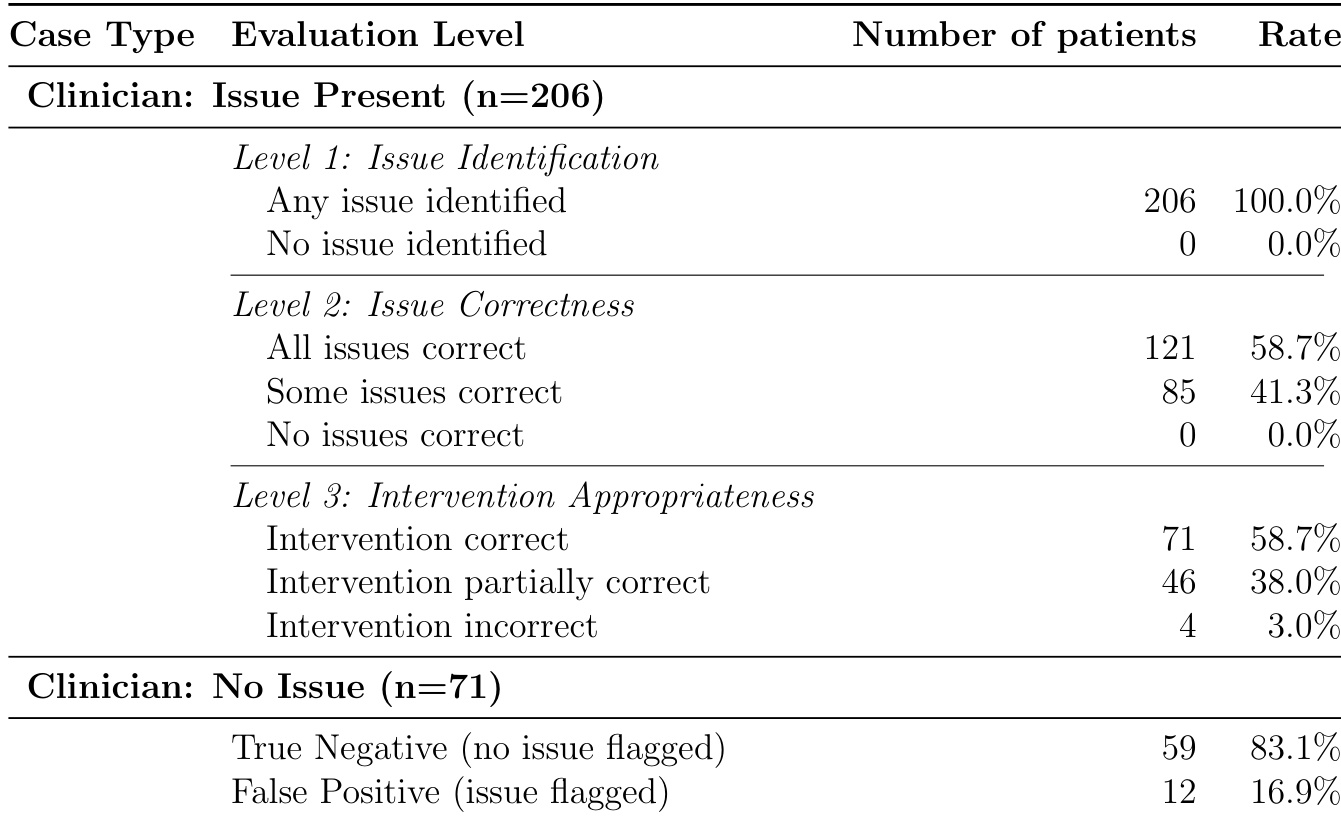
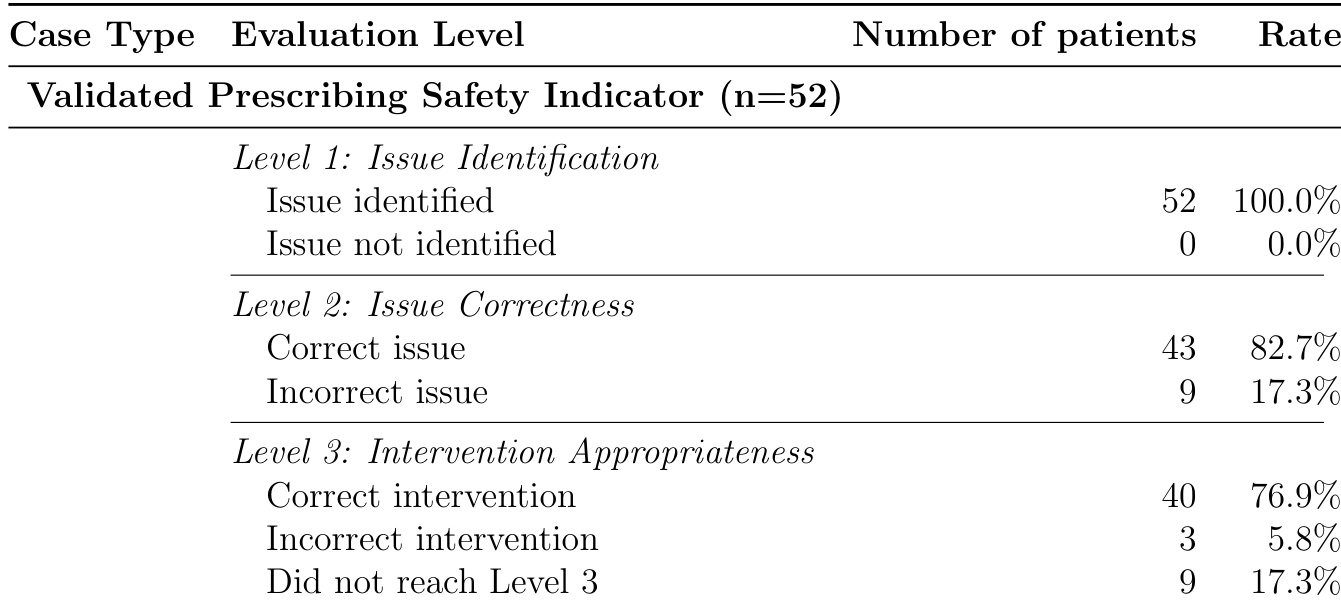
研究者在52例经临床验证的用药安全指标案例上评估LLM系统:1级敏感性100%,准确识别所有需干预问题;2级准确识别具体指标比例82.7%;3级在问题正确识别时提出适当干预比例76.9%。结果证明强检测能力,但随评估深度增加精度与干预质量下降。
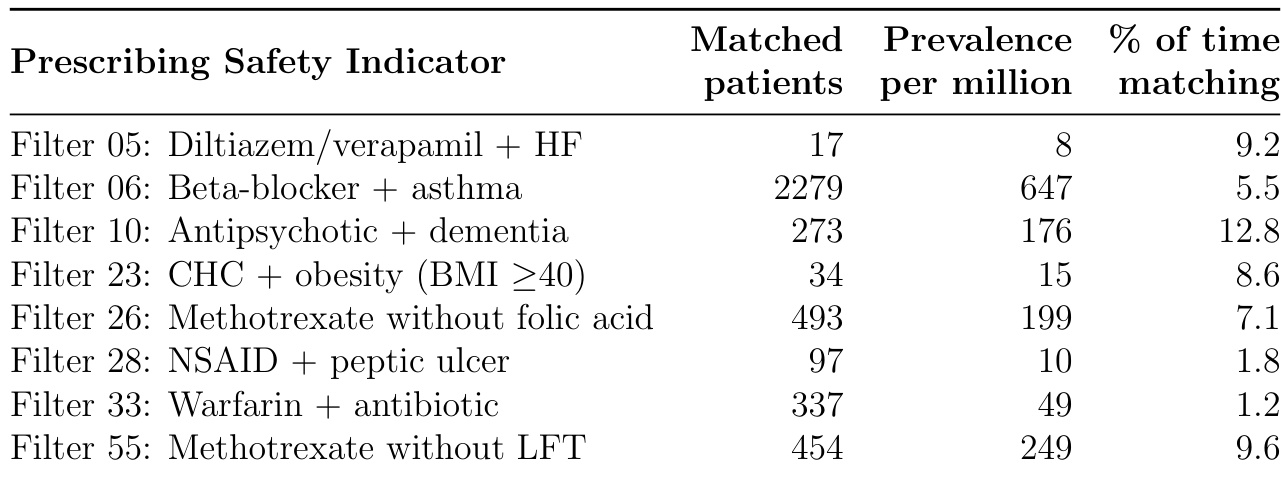
表格列出七项用药安全指标及其匹配患者数、百万人口患病率及患者符合标准的时间占比。Filter 06(β受体阻滞剂+哮喘)患病率最高(647/百万),Filter 28(NSAID+消化性溃疡)最低(10/百万)。患者符合各指标的时间占比差异显著:Filter 10(抗精神病药+痴呆)持续风险最高(12.8%),Filter 33(华法林+抗生素)最低(1.2%),反映短暂性药物相互作用。