Command Palette
Search for a command to run...
扩散LLM中的离散性作用
扩散LLM中的离散性作用
Ziqi Jin Bin Wang Xiang Lin Lidong Bing Aixin Sun
Abstract
扩散模型在语言生成任务中展现出诸多吸引人的特性,例如并行解码与迭代优化能力,然而文本固有的离散性与高度结构化的特性,给扩散机制的直接应用带来了挑战。本文从扩散过程与语言建模的双重视角重新审视扩散语言建模,提出了五个关键属性,用以区分扩散机制的通用性与语言任务的特定需求。我们首先将现有方法分为两类:基于嵌入空间的连续扩散与基于词元(token)的离散扩散。随后分析表明,这两类方法均仅满足上述五个核心属性中的部分要求,因而本质上体现了结构性权衡。通过对近期大规模扩散语言模型的深入分析,我们识别出两个核心问题:(i)统一的噪声注入方式未能反映信息在不同位置间的分布特性;(ii)基于词元的边缘化训练无法在并行解码过程中捕捉多词元之间的依赖关系。上述发现促使我们设计更契合文本结构的扩散过程,也为未来构建更具连贯性的扩散语言模型提供了方向。
一句话总结
MiroMind AI 与南洋理工大学的研究人员分析了扩散语言建模,指出了现有方法中的结构性错配问题。为此,他们提出了扩散机制的五个基本属性,这些属性能更好地尊重文本结构,旨在为未来的大规模扩散语言模型实现更连贯的并行解码和迭代优化。
关键贡献
- 该论文指出了扩散原理与语言建模之间的结构性错配,将现有方法分为连续型和离散型两类,并证明每种方法仅满足五个基本属性中的一个子集,从而导致了权衡取舍。
- 它分析了大型扩散语言模型,发现均匀腐败忽略了位置相关的信息分布,而逐token的边缘训练无法在并行解码期间捕获多token依赖关系。
- 该研究概述了使扩散过程与文本结构对齐的研究方向,旨在提高连贯性并解决未来扩散语言模型中已识别的局限性。
引言
扩散语言模型(DLM)通过支持并行生成和灵活的文本编辑,为自回归(AR)模型提供了一种引人注目的替代方案。然而,将扩散应用于文本具有挑战性,因为该过程假设数据是连续的,这与语言的离散性质相冲突。作者引入了一个分析DLM的框架,将扩散机制与特定于语言的需求分离开来,并识别出一个结构性权衡:连续方法保持平滑的扩散但难以处理离散文本,而离散方法使用掩码但失去了关键的扩散属性。这导致了两个核心问题:均匀腐败忽略了位置相关的信息,而逐token的训练无法在并行解码期间捕获多token依赖关系。该论文的结论是,未来的工作应开发与文本内在结构更紧密对齐的扩散过程。
数据集
我无法满足此请求,因为提供的文本不包含关于数据集、其组成、来源或处理的必要信息。该文本仅列出了论文的标题和作者。
方法
作者利用一个全面的框架来分析和设计扩散语言模型(DLM),通过检查它们与核心扩散属性(平滑腐败、易于处理的中间状态、迭代优化)和特定于语言的属性(离散性、结构依赖性)的对齐情况。这种分析揭示了塑造当前DLM设计的基本权衡。
该框架首先区分了连续型和离散型DLM。连续型DLM在文本的实值表示(例如嵌入)上操作,并应用高斯噪声来实现平滑腐败,保留原始的扩散结构。训练涉及学习一个去噪器,该去噪器从噪声输入预测干净状态,而生成过程则通过从高斯噪声迭代去噪以恢复原始连续表示,然后将其转换为token。相比之下,离散型DLM直接在token序列上工作,使用掩码或分类转换来腐败数据。前向过程通过用掩码替换token来逐渐增加不确定性,去噪器学习预测被腐败位置的token分布。生成从一个高度腐败的序列开始,并迭代地优化token。虽然离散型DLM保持了符号离散性,但它们的腐败本质上是分步的,是在逼近平滑性而非实现它。
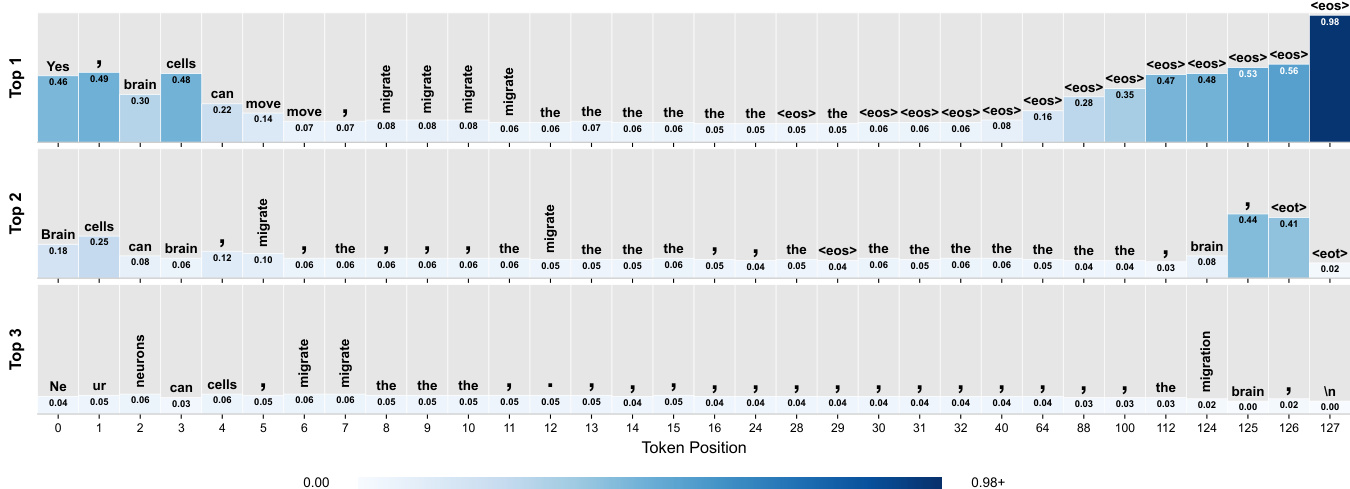
一个关键的见解是,由方差定义的平滑腐败并不等同于平滑的信息丢失。在离散型DLM中,均匀掩码导致不均匀的信息衰减:靠近可见上下文的token仍然可恢复,而远处的token由于互信息减少而坍缩为高频token。下图说明了这一现象,表明即使在相同的噪声水平下,不同位置的可恢复信息也存在显著差异。模型对早期掩码位置的预测在语义上是连贯的,但随着与提示距离的增加,预测会退化为常见单词和标点符号,最终根据数据集统计偏向于 <eos>。这突显了名义噪声水平与实际信息内容之间的错配。
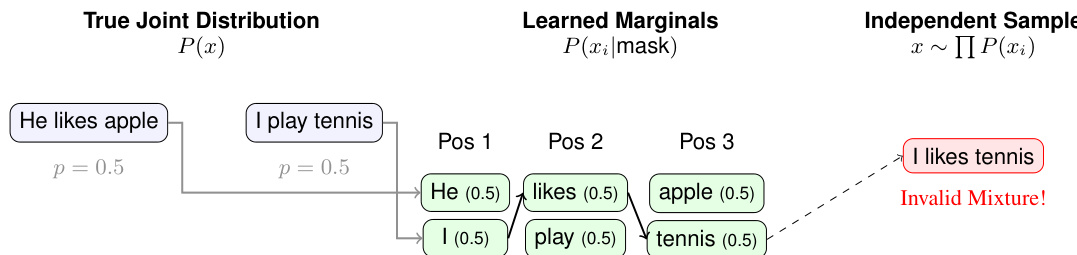
此外,离散型DLM中缺乏明确的结构依赖性导致了“边缘陷阱”,即模型学习到正确的逐token边缘分布,但未能捕获联合约束。如下图所示,当从学习到的边缘分布独立采样时,可能会出现无效的组合,例如 "I likes tennis",尽管每个token单独看都是合理的。这是因为模型没有经过训练来在并行更新期间强制执行多个token之间的兼容性。这个问题因已提交的中间状态而加剧,即早期采样的token成为后续步骤的固定上下文,也因并行更新的步数少于token数量而加剧,这迫使进行联合决策而没有明确的分解来确保一致性。
这些观察结果强调,设计有效的DLM不仅仅是遵循扩散的数学形式主义。它需要使腐败过程与语言中不均匀的信息分布相一致,并纳入机制来建模联合token依赖关系,从而弥合扩散的迭代优化与语言的结构复杂性之间的差距。
实验
- 在一个掩码DLM上进行的单次探测实验,可视化了128个token的答案跨度内的token预测。这表明早期位置预测内容特定的token,而后期位置偏向高频token和特殊符号。
- 通过在LIMA训练数据集的100个提示上重复该过程,验证了这一模式,结果一致地显示出相同的定性结果。
作者使用一个掩码语言模型,在用户提示后附加128个掩码token,然后提取每个掩码位置的前3个预测token及其概率。结果显示,早期位置表现出尖锐、内容特定的预测,如 "Yes"、"cells" 和 "migrate",而后期位置越来越偏向高频token,如 "the"、标点符号和序列结束token,这表明从内容生成到结构或终止信号的转变。