Command Palette
Search for a command to run...
评估参数高效方法在RLVR中的应用
评估参数高效方法在RLVR中的应用
Qingyu Yin Yulun Wu Zhennan Shen Sunbowen Li Zhilin Wang Yanshu Li Chak Tou Leong Jiale Kang Jinjin Gu
Abstract
我们系统地评估了在可验证奖励强化学习(Reinforcement Learning with Verifiable Rewards, RLVR)范式下参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)方法的表现。RLVR通过可验证的反馈机制激励语言模型提升其推理能力;然而,尽管LoRA等方法被广泛采用,针对RLVR场景的最优PEFT架构仍尚未明确。在本研究中,我们首次对超过12种PEFT方法在DeepSeek-R1-Distill系列模型上进行了全面评估,涵盖数学推理基准测试。实验结果挑战了默认采用标准LoRA的惯例,得出三大核心发现:第一,结构化变体方法(如DoRA、AdaLoRA和MiSS)在各项指标上均显著优于标准LoRA;第二,我们揭示了基于SVD初始化策略(如PiSSA、MiLoRA)中存在的谱坍缩(spectral collapse)现象,其失败根源在于主成分更新方向与强化学习优化目标之间存在根本性错配;第三,消融实验表明,极端参数压缩(如VeRA、Rank-1)会严重制约模型的推理能力。此外,我们通过系统的消融分析与规模扩展实验进一步验证了上述结论。本研究为推动参数高效强化学习方法的深入探索提供了明确且具有指导意义的实践依据。
一句话总结
浙江大学、港科大、武科大、中国科大、布朗大学、香港理工大学和INSAIT提出,结构化变体如DoRA在可验证奖励强化学习(RLVR)数学推理任务中优于标准LoRA,因其与强化学习的非主轴优化动态更契合;而基于SVD的初始化因谱失配失败,极端参数压缩则造成表达能力瓶颈。
主要贡献
-
本工作解决了强化学习中可验证奖励(RLVR)场景下的高效训练挑战,其中稀疏的二值反馈限制了全参数微调的有效性,因此需要参数高效方法在降低计算成本的同时保持推理性能。
-
研究发现,LoRA的结构化变体(如DoRA、AdaLoRA和MiSS)在RLVR中始终优于标准LoRA,而基于SVD的初始化策略(如PiSSA、MiLoRA)因谱崩溃失败,表明其更新机制与RL的稀疏优化动态存在根本性不匹配。
-
在DeepSeek-R1-Distill系列模型上对数学推理基准的实证评估表明,极端参数压缩(如VeRA、Rank-1)严重削弱推理能力,消融实验进一步证实了这些发现对多种训练配置和损失类型的鲁棒性。
引言
作者研究了在强化学习中可验证奖励(RLVR)背景下参数高效微调(PEFT)方法的应用,该范式通过稀疏的二值反馈提升语言模型的推理能力。尽管LoRA已成为RLVR中的默认PEFT方法,但其在强化学习特有的优化动态——稀疏监督与非主轴更新——下的适用性尚未得到验证。以往研究大多忽视了PEFT变体在此场景下的性能差异,而基于SVD的初始化策略尽管理论上有潜力,却表现出意外失败。作者首次对超过12种PEFT方法在多个模型和数学推理基准上进行了全面评估,发现DoRA、AdaLoRA和MiSS等结构化变体始终优于标准LoRA。他们识别出SVD相关方法中的谱崩溃现象,归因于主成分更新与RL优化之间的不匹配。此外,他们还表明极端参数压缩严重限制了推理能力。这些发现挑战了现有范式,倡导在RLVR中更审慎地选择PEFT架构,强调结构设计而非单纯参数数量。
方法
作者利用强化学习中可验证奖励(RLVR)来增强大语言模型(LLM)的推理能力,通过引入确定性验证器提供稀疏但准确的二值反馈。该方法能够激发自修正和迭代优化等复杂行为,区别于传统的RLHF。近年来该领域许多进展的基础框架是组相对策略优化(GRPO),其通过组级统计量估计优势,无需独立的评判模型。对于给定提示 q,GRPO 采样一组 G 个响应 {o1,…,oG},并优化以下代理目标:
IGRPO(θ)=Eq∼D,{oi}∼πθoldG1i=1∑G∣oi∣1t=1∑∣oi∣min(πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)A^i,clip(πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t),1±ϵ)A^i)其中 A^i=std({Ri})(Ri−mean({Rj})) 表示组内标准化优势。该公式允许在批次内对响应进行相对比较,推动基于相对表现而非绝对奖励值的策略更新。
为应对长思维链(CoT)场景中的熵崩溃和训练不稳定性,已提出若干GRPO优化变体。其中之一是解耦剪裁与动态采样策略优化(DAPO),其通过将剪裁范围解耦为 ϵlow 和 ϵhigh 引入“剪裁更高”策略。通过设置较大的 ϵhigh(如0.28),DAPO允许对低概率词元进行更大范围探索,从而维持策略多样性。此外,DAPO采用动态采样机制,过滤掉所有输出均获得相同奖励(全0或全1)的提示,确保梯度信号一致并提升样本效率。
另一项改进是Dr. GRPO,其解决了原始GRPO公式中存在的系统性偏差。Dr. GRPO移除了每响应长度归一化项 ∣oi∣1,该项可能无意中偏好较长的错误响应而非简洁的正确响应。此外,它还消除了优势估计中的组级标准差,以缓解难度偏差问题——即奖励方差较低(过易或过难)的问题被赋予过高权重。这些修改提升了训练过程的鲁棒性与公平性。
沿用先前工作,作者采用DAPO作为标准训练算法,将其作为对比分析的基线,而其他方法则作为消融实验处理。
实验
- 在MATH-500、AIME、AMC、Minerva和HMMT基准上,使用DeepSeek-R1-Distill模型对12种PEFT方法在RLVR中进行了大规模评估,验证了结构化变体优于标准LoRA。
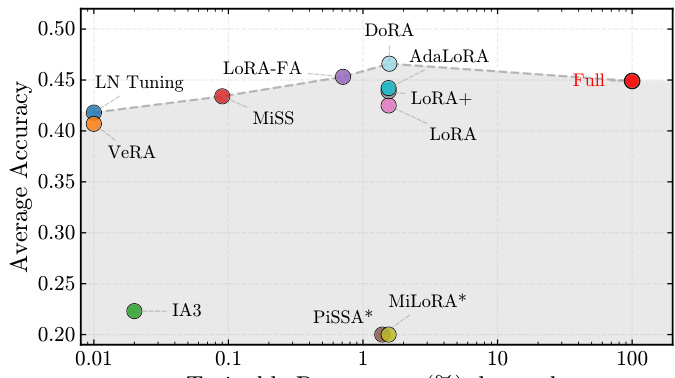
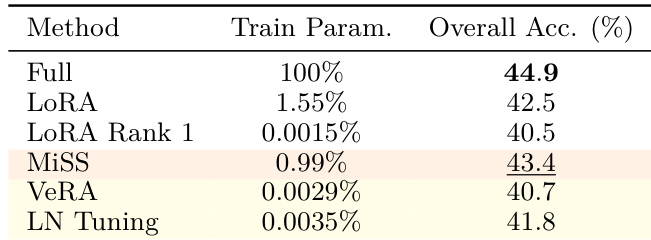
- 结构化变体(DoRA、MiSS、AdaLoRA)始终优于标准LoRA和全参数微调,DoRA在AIME和AMC等关键基准上达到46.6%的平均准确率,超过全参数微调(44.9%)。
- 基于SVD的初始化策略(如PiSSA、MiLoRA)因与RLVR的非主轴更新动态存在结构不匹配而失败;PiSSA准确率跌至0.2%,MiLoRA虽理论上对齐,仍退化至18.0%。
- 极端参数压缩方法(VeRA、IA³、LN-tuning)导致性能崩溃(如VeRA为40.7%,IA³为22.3%),揭示了RLVR中存在关键的表达能力下限,需足够可训练容量以支持复杂推理。
- 消融实验表明,学习率缩放、中等LoRA秩(r=16, 32)和更大批量可提升性能,而RLVR算法选择对PEFT效果影响较小。
- 扩展至7B模型后结果一致:DoRA和LoRA+达到55.0%的平均准确率,证实了发现的跨模型规模泛化性。
作者使用全面基准评估了强化学习中可验证奖励的参数高效方法,聚焦数学推理任务。结果表明,标准LoRA表现逊于结构化变体如MiSS,后者在使用更少可训练参数的情况下仍实现更高准确率;而极端压缩方法如VeRA和LN Tuning导致显著性能下降。
作者使用大规模基准评估了超过12种参数高效微调方法在强化学习中可验证奖励中的表现,发现标准LoRA并非最优,结构化变体如DoRA和MiSS始终优于它,甚至常超越全参数微调。结果表明,基于SVD的初始化策略因与强化学习非主轴更新动态的根本性不匹配而失败,而极端参数压缩方法则因造成表达能力瓶颈导致性能崩溃。

作者使用大规模基准评估了强化学习中可验证奖励的参数高效方法,聚焦数学推理任务。结果表明,DoRA和LoRA+等结构化变体在多个基准上均优于标准LoRA,DoRA实现最高平均准确率,并在关键任务上持续超越全参数微调。

作者进行消融研究以评估关键训练超参数对参数高效强化学习的影响。结果表明,尽管批量大小和学习率有一定影响,但RLVR算法选择和LoRA秩对性能影响更大,较高秩及特定算法可带来更优结果。

作者采用谱分析方法研究不同参数高效方法在强化学习中可验证奖励中的更新动态。结果表明,PiSSA和MiLoRA等基于SVD的初始化策略因与RLVR非主轴更新动态的结构不匹配而失败,导致性能崩溃,尽管其理论上具备对齐性。相比之下,DoRA和MiSS等结构化变体通过更好地契合RLVR的优化景观,实现了更优的推理准确率。