Command Palette
Search for a command to run...
LiveTalk:通过改进的自洽蒸馏实现实时多模态交互式视频扩散
LiveTalk:通过改进的自洽蒸馏实现实时多模态交互式视频扩散
Ethan Chern Zhulin Hu Bohao Tang Jiadi Su Steffi Chern Zhijie Deng Pengfei Liu
Abstract
通过扩散模型实现实时视频生成,对于构建通用型多模态交互式人工智能系统至关重要。然而,现有扩散模型在迭代过程中采用双向注意力机制对所有视频帧进行同步去噪,这一特性严重限制了实时交互的实现。尽管现有的知识蒸馏方法可通过使模型具备自回归特性并减少采样步数来缓解该问题,但其主要聚焦于文本到视频生成任务,导致人机交互过程自然度不足且效率较低。本文致力于实现基于多模态上下文(包括文本、图像和音频)的实时交互式视频扩散生成,以弥合这一技术鸿沟。基于观察发现,当前领先的在线策略蒸馏方法——Self Forcing 在多模态条件输入下面临显著挑战,表现为视觉伪影(如闪烁、黑帧及画质下降)等问题。为此,本文提出一种改进的蒸馏方案,重点优化条件输入的质量,以及在线策略优化过程中的初始化方式与调度策略。在包含 HDTF、AVSpeech 和 CelebV-HQ 在内的多模态条件驱动(音频、图像、文本)虚拟形象视频生成基准测试中,所提出的蒸馏模型在视觉质量上达到与同等规模或更大规模的全步长双向基线模型相当的水平,同时推理成本和延迟降低约20倍。进一步地,我们将该模型与音频语言模型及长视频推理技术 Anchor-Heavy Identity Sinks 相结合,构建了名为 LiveTalk 的实时多模态交互式虚拟形象系统。在自建的多轮交互评测基准上的系统级评估表明,LiveTalk 在多轮视频连贯性与内容质量方面超越当前最先进的模型(如 Sora2、Veo3),并将响应延迟从原先的1至2分钟显著缩短至实时生成水平,实现了流畅自然的人机多模态交互体验。
一句话总结
来自SII、SJTU和GAIR的作者提出了一种蒸馏后的多模态扩散模型,能够基于文本、图像和音频实现实时交互式视频生成,推理速度比双向基线快20倍,同时通过改进的策略内蒸馏(包含更优的输入条件和优化调度)保持了高视觉质量;集成至LiveTalk系统后,该系统实现了无缝、低延迟、多轮的人机交互,相比Sora2和Veo3在连贯性和内容质量方面表现更优。
主要贡献
-
本文解决了实时交互式视频生成的挑战,使多模态条件扩散模型(文本、图像、音频)能够在自回归模式下高效运行,克服了双向、多步扩散模型带来的高延迟问题,后者严重阻碍了实时人机交互。
-
提出了一种改进的蒸馏框架,在复杂多模态条件下通过优化输入条件、收敛的ODE初始化以及激进的优化调度,稳定了策略内训练,显著减少了闪烁、黑帧等视觉伪影,同时保持了高保真输出。
-
在HDTF、AVSpeech和CelebV-HQ基准上评估,该蒸馏模型实现20倍更快的推理速度和亚秒级延迟,相比双向基线表现优异;当集成至LiveTalk系统并采用Anchor-Heavy Identity Sinks技术时,实现了实时、长时、连贯的多轮虚拟形象交互,无论在质量还是响应速度上均优于Sora2和Veo3。
引言
实时多模态交互式视频生成对于构建能够使用文本、图像和音频输入进行动态对话的自然、响应迅速的AI虚拟形象至关重要。然而,标准扩散模型依赖于计算成本高昂的双向去噪过程,覆盖所有帧,导致延迟高达1–2分钟,难以满足实时交互需求。尽管先前的蒸馏方法实现了更快的自回归生成,但主要针对文本到视频任务,在多模态条件下的表现不佳,常出现闪烁、画质下降等视觉伪影。作者通过引入一种改进的策略内蒸馏框架,解决了这一问题:通过三大关键改进——高质量、以运动为中心的多模态条件;策略内训练前的ODE初始化收敛;以及经过调优的分类器引导的激进优化调度,显著提升了训练稳定性。所提出的蒸馏模型实现了20倍更快的推理速度,延迟低于1秒,同时在视觉质量上达到或超越更大规模的双向基线模型。在此基础上,作者开发了LiveTalk系统,一个实时交互式虚拟形象系统,集成了音频语言模型和一种新颖的Anchor-Heavy Identity Sinks技术,以维持长期视觉一致性。系统评估表明,LiveTalk在多轮连贯性、内容质量和响应延迟方面均优于Sora2和Veo3,实现了无缝、类人化的多模态交互体验。
数据集
- 数据集由九个不同的评估维度组成,旨在评估多模态模型的视觉交互性能与交互内容质量。
- 每个维度均采用针对特定评分标准定制的结构化提示,确保任务间评估的一致性与可度量性。
- 评估框架通过多轮协议实现,由视觉-语言模型(VLM)处理每个提示并生成用于评分的响应。
- 数据集支持定性与定量分析,提供详细的实现指南以确保可复现性。
- 数据用于模型训练与评估流程,以优化交互能力,混合比例与划分配置经过调优,确保各维度间平衡表示。
- 未进行显式裁剪或元数据构建,重点在于提示工程与响应对齐,以确保对交互动态的高保真评估。
方法
作者采用两阶段蒸馏框架,将一个双向、多步扩散模型转化为适用于实时视频生成的因果、少步自回归(AR)模型。整体架构如图所示,将蒸馏后的视频扩散模型与大语言模型结合,构成完整的实时多模态交互系统。该方法的核心包括ODE初始化阶段,随后是基于分布匹配蒸馏(DMD)的策略内蒸馏。

在ODE初始化阶段,学生模型被训练从教师模型去噪轨迹中采样的少数时间步中预测干净的潜在帧 x0。这通过最小化轨迹蒸馏损失实现,促使学生在特定时间步匹配教师的输出。学生模型设计为以块状方式生成视频,每个块包含多个潜在帧,支持高效流式传输。该架构支持因果注意力和键值(KV)缓存,用于自回归生成,通过预填充前一块的干净KV缓存,保持块间视觉一致性。
在完成ODE初始化后,模型进入策略内蒸馏阶段,采用DMD方法以缓解暴露偏差。该阶段包含一个生成器 gϕ 和一个可训练的判别器 sψ,以及一个冻结的教师评分网络 sθ。判别器通过最小化去噪目标学习追踪生成器的演化分布,而生成器则被更新以使其输出与教师评分对齐。生成器的梯度更新结合了教师与判别器评分之间的差异,确保生成器学习产生与教师分布一致的输出。该过程通过自生成的滚动(rollouts)进行,即模型生成序列后用于训练。
系统进一步引入多项改进以增强蒸馏过程。多模态条件经过优化,提供高质量训练信号,针对图像和文本输入采用基于数据集特性的专门筛选策略。ODE初始化训练至收敛,以建立稳健的起点;在DMD阶段采用激进的学习率调度,以在有限的有效窗口内最大化学习效率。这些改进确保了生成视频中音频与视觉的高度对齐及高视觉质量。
蒸馏模型被集成至实时交互系统中,作为表演模块,渲染同步说话的虚拟形象。系统采用重叠窗口化处理音频条件,以提供丰富的声学上下文,同时保持实时响应能力。为在长视频流中保持说话人身份一致性,采用一种无需训练的方法——Anchor-Heavy Identity Sinks(AHIS),将部分KV缓存分配为身份锚点,用于存储高保真早期帧。此外,采用流水线并行技术,使扩散去噪与VAE解码并行执行,降低每块延迟,实现无阻塞流式传输。
实验
- 识别出现有蒸馏方案中的三个关键问题:因参考图像质量低导致的数据质量问题;ODE初始化不足引发的训练不稳定;以及学习窗口有限导致的多模态视频扩散蒸馏过早退化。
- 提出并验证了四项改进:高质量多模态条件的筛选、收敛的ODE初始化(20k步)、激进的学习率调度,以及调优的教师评分CFG引导,这些措施共同消除了视觉退化,显著提升了稳定性。
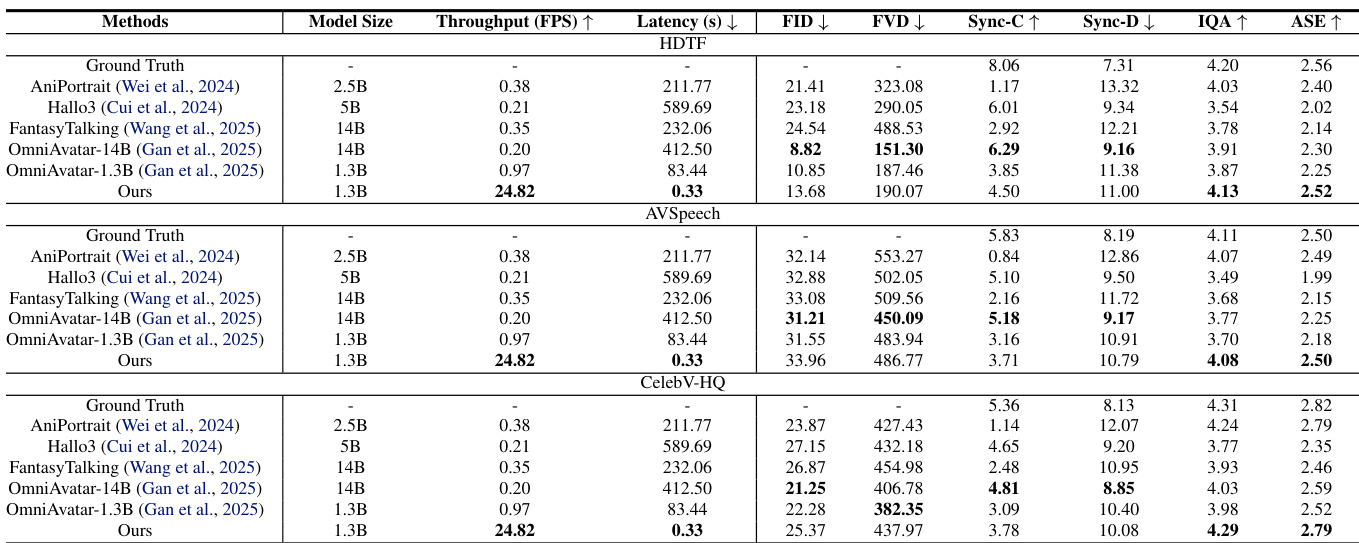
- 在HDTF、AVSpeech和CelebV-HQ基准上,蒸馏模型在视觉质量(FID、FVD、IQA、ASE)、唇形同步精度(Sync-C/D)和对话连贯性方面达到或超过更大规模的双向模型(如OmniAvatar-1.3B、14B),同时实现25倍更高的吞吐量(24.82 FPS vs. 0.97 FPS)和250倍更快的首帧延迟(0.33s vs. 83.44s)。
- 在基于VLM的多轮交互评估中,该模型在多视频连贯性和内容质量上优于Veo3和Sora2,通过AR生成结合KV缓存与Qwen3-Omni记忆机制,展现出更优的时间一致性与上下文感知能力。
- 消融实验确认每个提出组件均对性能有增量贡献,其中高质量数据筛选与收敛的ODE初始化对稳定且高质量的蒸馏至关重要。
作者进行消融研究以评估四项关键改进对蒸馏质量的影响,结果表明每个组件均对性能有逐步提升。最终配置在所有指标上均取得最佳表现,尤其在FID、FVD、Sync-C和Sync-D上提升显著;而缺乏高质量多模态条件则导致质量大幅下降,凸显了数据质量的关键作用。

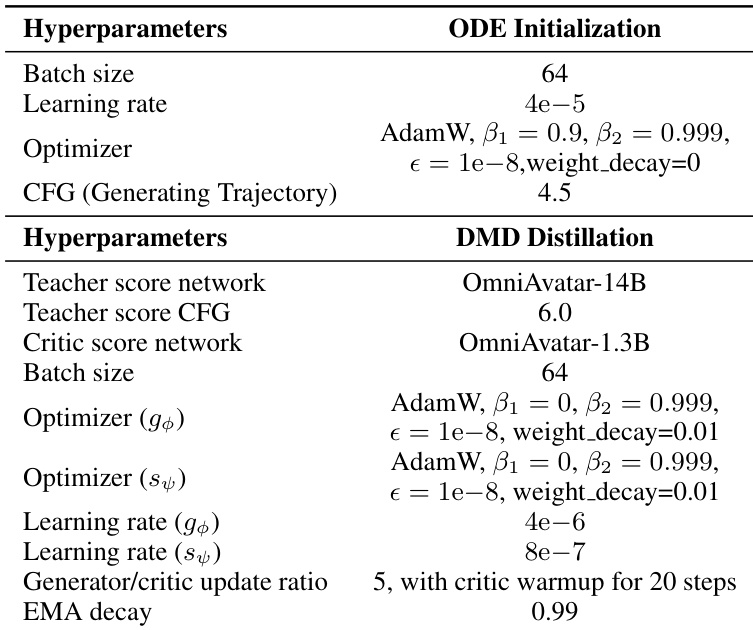
作者采用包含ODE初始化与DMD蒸馏的两阶段蒸馏流程,各阶段使用不同的超参数。结果显示,DMD蒸馏阶段采用生成器与判别器网络5:1的更新比例,判别器在生成器训练开始前先更新20步,并从第200步起采用0.99的EMA衰减率。
作者在多轮交互基准上将蒸馏模型与基线Veo3和Sora2进行对比,结果显示LiveTalk在多视频连贯性和内容质量指标上均优于两者,同时在其他视觉交互维度上保持竞争力。LiveTalk通过结合KV缓存的AR生成与Qwen3-Omni模块的文本记忆,实现了连贯的多轮生成,显著降低延迟并提升吞吐量。

作者使用蒸馏模型在多模态虚拟形象生成基准上与多个基线进行性能对比,结果在视觉质量、美学和唇形同步精度方面达到或超过更大规模的双向模型,同时显著提升吞吐量与延迟表现。结果显示,该蒸馏模型在域内与域外数据集上均优于或匹配OmniAvatar-1.3B和OmniAvatar-14B等模型,吞吐量提升25倍,首帧延迟超过250倍加快。