Command Palette
Search for a command to run...
开放性推理的扩展以预测未来
开放性推理的扩展以预测未来
Nikhil Chandak Shashwat Goel Ameya Prabhu Moritz Hardt Jonas Geiping
Abstract
高风险决策涉及对未来不确定性的推理。在本研究中,我们训练语言模型以回答开放式的预测性问题。为扩大训练数据规模,我们利用每日新闻中报道的全球事件,通过一种完全自动化且经过精心设计的筛选流程,自动生成新颖的预测问题。我们基于自建数据集 OpenForesight,对 Qwen3 思维模型进行训练。为防止训练和评估过程中出现未来信息泄露,我们的预测系统在数据生成与检索环节均采用离线新闻语料库。在少量验证集的引导下,我们验证了检索机制的有效性,以及改进后的强化学习奖励函数所带来的性能提升。在构建最终预测系统后,我们于2025年5月至8月期间开展保留测试(held-out testing)。我们提出的专用模型 OpenForecaster 8B,在预测准确性、校准性与一致性方面,达到了远超其规模的专有大模型水平;且训练过程显著提升了模型的预测质量。我们进一步发现,通过预测训练获得的校准性提升,可在多个主流基准测试中实现泛化。为推动语言模型预测研究的广泛可及性,我们已开源全部模型、代码与数据。
一句话总结
来自马克斯·普朗克智能系统研究所、艾利斯图宾根研究所、图宾根人工智能中心和图宾根大学的作者提出了 OpenForecaster8B,这是一个在 OpenForesight——一个从精选新闻中合成生成的预测问题数据集——上训练的专用语言模型,采用离线数据以防止信息泄露,通过检索机制和改进的强化学习奖励函数提升预测准确性、校准度和一致性,其表现优于更大规模的专有模型,并在多个基准上展现出泛化能力,所有资源均已开源。
主要贡献
-
本文解决了训练语言模型进行开放式预测——即预测无结构、自然语言描述的事件而无需预定义结果集——的挑战,提出了一种可扩展的方法,从每日新闻中生成多样化的现实世界预测问题,克服了现有数据源(如预测市场)范围狭窄、存在偏见且数据量低的局限性。
-
作者开发了 OpenForecaster8B,一个在 OpenForesight 数据集上训练的专用模型,采用精心设计的流水线,通过依赖离线新闻快照进行数据生成和检索,避免未来信息泄露,并通过检索增强推理和在组相对策略优化(GRPO)中改进的奖励函数提升性能。
-
在 2025 年 5 月至 8 月的保留数据上评估,该模型在准确性、校准度和一致性方面达到与更大规模专有模型相当的水平,校准度提升在多个基准上具有泛化性,整个系统(包括模型、代码和数据)均已开源,以推动语言模型预测领域的可访问性研究。
引言
作者针对训练大型语言模型(LLMs)用于开放式预测——即在无预定义结果选项的情况下预测以自然语言描述的未来事件——的挑战展开研究。这一任务对于捕捉科学突破或地缘政治变动等意外且高影响力的发展至关重要,而传统预测市场依赖二元或多项选择题,往往难以覆盖此类事件。先前工作存在局限:人工筛选问题导致数据稀缺,二元结果占主导地位造成强化学习信号噪声大,且分布偏向特定领域(如美国政治或加密货币)。为克服这些问题,作者提出一种可扩展的流水线,能从静态的月度新闻快照中自动生成高质量的开放式预测问题。通过多阶段流程——使用 DeepSeek-v3 进行问题生成,Llama-4-Maverick 进行验证,以及泄漏消除——确保问题具有明确性、可回答性且不含答案提示。随后,作者使用组相对策略优化(GRPO)结合 Brier 评分训练模型,使模型在准确性和校准度上均得以提升。该方法表明,开放式预测可有效扩展,8B 模型的表现可与专有模型竞争,同时在分布外事件上也展现出泛化能力。
数据集
-
该数据集名为 OpenForesight,基于 2023 年 6 月至 2025 年 4 月期间从 Forbes、CNN、Hindustan Times、Deutsche Welle 和 The Irish Times 等全球多样化媒体收集的约 248,000 篇去重英文新闻文章构建,数据来源于 CommonCrawl News (CCNews) 语料库,该语料库提供静态、时间准确的快照,防止未来信息泄露。
-
从每篇新闻文章中,一个样本生成模型(DeepSeek v3)最多生成三个预测问题,每个问题包含:关于事件预测的问题、简要背景(含定义)、分辨率标准(真实来源、分辨率日期、答案格式)、一个逐字短答案(1–3 个词,非数值,通常为名称或地点),以及指向原始文章的链接。
-
生成后,数据集经过多轮过滤:60% 的候选问题因模糊或缺乏明确分辨率而被剔除;对于产生多个有效问题的文章,通过样本选择器(Llama-4-Maverick)选出最佳问题;排除数值答案;并通过模型重写、拒绝和最终字符串匹配过滤解决直接答案泄露问题。
-
最终数据编辑步骤确保所有问题在 2024 年 1 月 1 日之后可解决,仅保留具有有效、无歧义分辨率标准的问题。该流程将初始约 745,000 个样本缩减为最终 52,000 个高质量、唯一的样本。
-
验证集由 2025 年 7 月从随机抽取的 500 篇《卫报》文章中生成的 207 个问题构成,使用更强大的模型(o4-mini-high)以提升质量,实现 40% 的保留率。
-
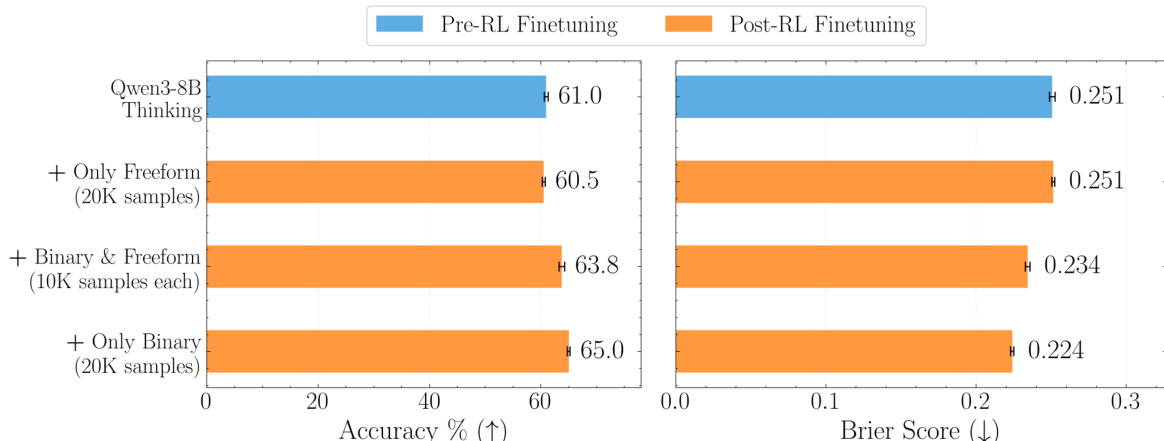
该数据集用于训练包含自由格式和二元问题的预测模型,实验表明结合两种类型可获得最佳性能。在 OpenForesight 上训练显著提升了准确性和 Brier 分数,即使在缩放后也超越更大模型。
-
答案类型以人物和地点(65%)及杂项实体(35%)为主,反映了对个人、地点、组织、团队及其他命名实体的广泛覆盖。
-
每个问题均明确定义分辨率标准,包括可验证的真实来源、固定分辨率日期和精确答案格式,确保评估的一致性和可靠性。
-
测试集经过人工筛选,排除存在多个答案、未解决的未来事件、小众相关性或已确立事实的问题,确保仅包含有效且可回答的问题。
方法
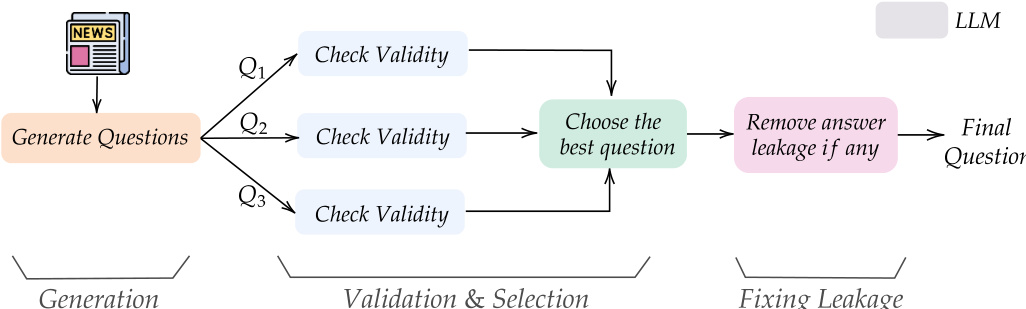
作者采用多阶段流水线,从新闻文章中生成并整理开放式预测问题,构成其训练数据集 OpenForesight 的基础。流程始于输入新闻文章,由语言模型生成多个候选问题。随后进入验证与选择阶段,由另一语言模型评估每个问题是否符合特定标准:问题-答案对必须基于源文章,问题必须具有前瞻性(如使用将来时态),且答案必须明确、无歧义,并可在指定日期内解决。此验证步骤确保生成问题的质量与相关性。从单篇文章衍生的多个问题中,系统选择最佳问题,优先考虑具有清晰、唯一答案且相关性高的问题,以增强数据多样性。验证后,进入最终编辑阶段,处理潜在的信息泄露问题,模型检查问题标题、背景和分辨率标准中是否存在关于答案的直接或间接提示。若检测到泄露,模型使用通用占位符重写相关部分。这一严格的整理流程确保最终数据集兼具高质量且无未来信息偏差。
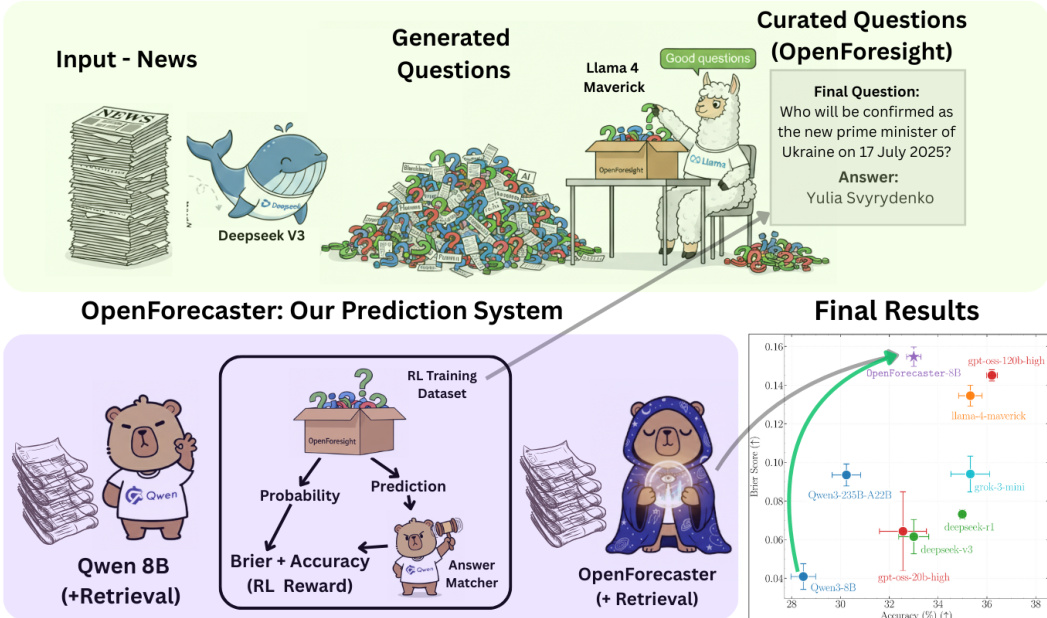
核心预测系统名为 OpenForecaster,基于 Qwen 8B 模型构建,并引入检索增强生成以提升预测性能。系统以预测问题为输入,生成预测结果,随后由答案匹配器评估预测正确的概率。该概率连同预测的准确性共同用于计算强化学习(RL)奖励,该奖励旨在优化简洁性与准确性。RL 训练数据集来源于 OpenForesight 数据集,模型通过此奖励信号训练以提升其预测能力。系统设计为检索增强型,可访问外部信息以支持预测,这对预测任务尤为重要,因为相关背景信息可能无法完全包含在问题本身中。
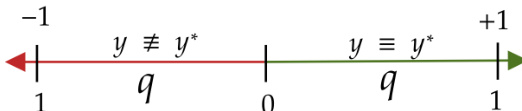
作者采用一种强化学习奖励函数,旨在提升模型预测的校准度。该奖励函数基于模型预测概率与实际结果之间的差异,对过度自信施加惩罚。奖励定义为 R=21(1+∣y−y∗∣y−y∗),其中 y 为模型预测概率,y∗ 为实际结果(正确为 1,错误为 0)。该奖励函数鼓励模型实现良好校准,即某概率水平的预测应大致在该比例时间内正确。该奖励函数用于强化学习训练,目标是提升预测的准确性、校准度和一致性。
实验
- 奖励设计消融实验表明,结合准确性和 Brier 分数可同时提升准确性和校准度,优于仅使用准确性或仅使用 Brier 分数的基线奖励;混合奖励减少了对低置信度“未知”预测的过度依赖。
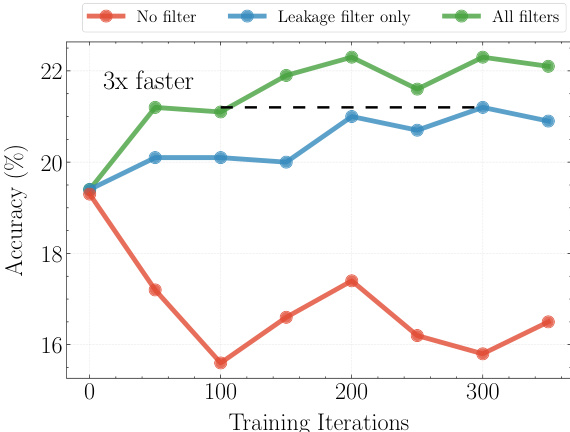
- 从精选的 CCNews 语料库中检索最多五个相关新闻片段(每个 512 个 token)显著提升准确率 9–18%,性能在超过五个片段后趋于饱和。
- 在 OpenForesight 数据集(50,000 个样本)上使用检索和所提奖励函数训练,使开放式预测表现强劲:OpenForecaster8B 的 Brier 分数超越 GPT OSS 120B,准确率超过 Qwen3 235B,在 Llama 3.1 8B 上实现 25% 的绝对准确率提升。
- 在外部 FutureX 基准(86 个问题)上,OpenForecaster8B 达到最高准确率和接近最佳的 Brier 分数,优于更大规模的专有模型。
- 校准度提升在其他领域也具有泛化性:OpenForecaster8B 在 SimpleQA、MMLU-Pro 和 GPQA-Diamond 上均取得显著进步,通过简单的置信度阈值实现更好的不确定性估计并减少幻觉。
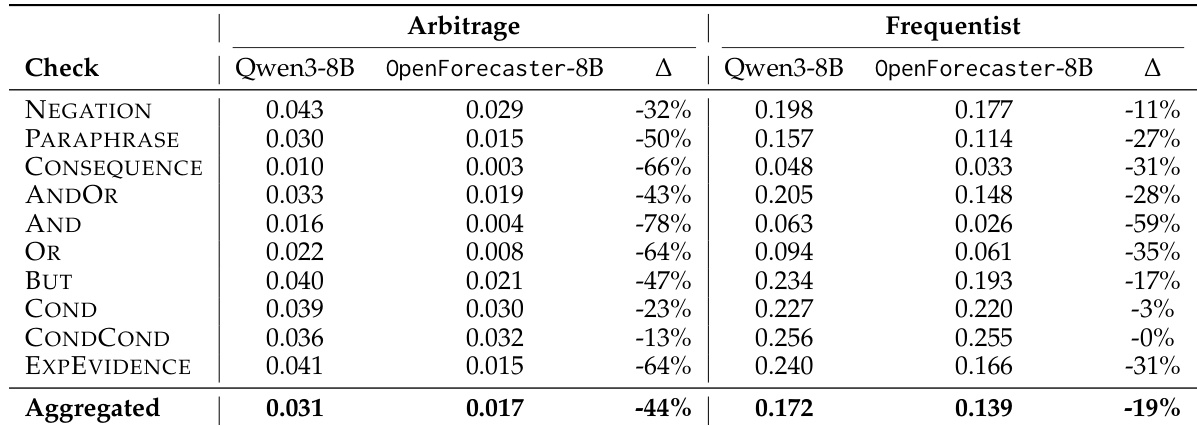
- 长期预测一致性在套利指标上提升 44%,在频率指标上提升 19%,表明模型随时间推理更具逻辑一致性。
- 消融研究证实,自由格式预测数据对开放式性能至关重要,而结合二元与自由格式数据在各项评估任务中取得最佳权衡。
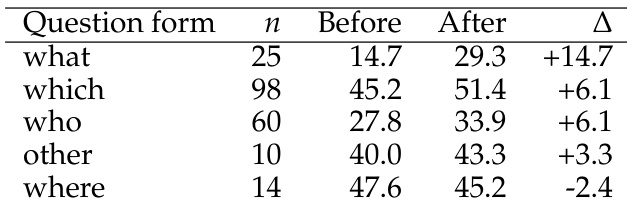
- 定性分析显示,“谁”、“什么”和“哪个”类问题的准确性和置信度校准均有提升,但“哪里”类问题性能略有下降,且在实体混淆或信息缺失情况下表现退化。
作者采用结合准确性和 Brier 分数的奖励机制训练模型,相比单独使用任一指标,显著提升了准确性和校准度。结果表明,所提出的奖励设计增强了探索能力,减少了对“未知”预测的过度使用,从而整体提升了预测性能。
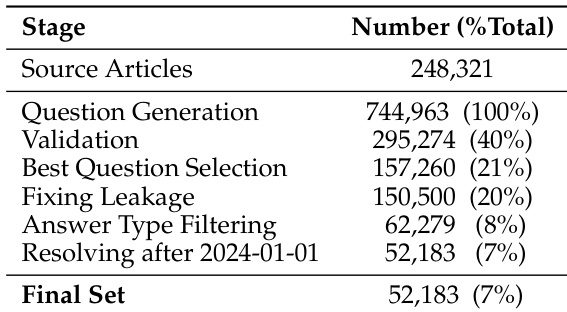
作者采用多阶段流程整理其数据集,初始有 248,321 篇源文章,生成 744,963 个问题。经过过滤与验证步骤后,最终数据集包含 52,183 个样本,其中 7% 的初始文章贡献了最终数据集。
作者使用表格评估 Qwen3-8B 和训练后的 OpenForecaster-8B 模型在长期预测问题上的概率预测一致性。结果显示,训练后的模型在多数一致性检查中显著降低违规分数,套利违规减少 44%,频率违规减少 19%,相较于基线。这表明训练过程提升了模型推理的逻辑一致性。
作者使用包含 5 个片段上下文的检索系统以提升预测准确性,结果表明引入检索在各模型上均带来显著准确率提升。绿色曲线代表所有过滤器均启用的模型,始终优于其他两种配置,准确率更高,表明过滤有效提升了性能。
结果显示,模型在“什么”、“哪个”和“谁”类问题上的表现显著提升,平均准确率分别提高 14.7、6.1 和 6.1 分。然而,“哪里”类问题表现下降 2.4 分,表明其在地理位置预测方面存在特定弱点。