Command Palette
Search for a command to run...
GDPO:面向多奖励强化学习优化的分组奖励解耦归一化策略优化
GDPO:面向多奖励强化学习优化的分组奖励解耦归一化策略优化
Abstract
随着语言模型能力的不断提升,用户不仅期望其提供准确的回答,还希望模型在各类场景下展现出与多样化人类偏好相一致的行为。为实现这一目标,强化学习(Reinforcement Learning, RL)流水线逐渐引入多种奖励信号,每种奖励捕捉一种特定偏好,以引导模型趋向期望行为。然而,近期研究在多奖励设定下普遍采用群体相对策略优化(Group Relative Policy Optimization, GRPO),却未对其适用性进行充分检验。本文揭示,直接将GRPO应用于不同轨迹奖励组合的归一化处理时,会导致各类奖励组合的优势值趋于完全相同,从而降低训练信号的分辨能力,引发次优收敛,甚至在某些情况下导致训练过早失败。为此,我们提出一种新的策略优化方法——群体奖励解耦归一化策略优化(Group reward-Decoupled Normalization Policy Optimization, GDPO),通过解耦各奖励信号的归一化过程,更真实地保留其相对差异,从而实现更精确的多奖励优化,并显著提升训练稳定性。我们在三个任务上对GDPO与GRPO进行了对比评估:工具调用、数学推理和代码推理,综合考察了正确性指标(准确率、错误率)与约束遵循性指标(格式、长度)。在所有实验设置中,GDPO均持续优于GRPO,充分验证了其在多奖励强化学习优化中的有效性与通用性。
一句话总结
来自华盛顿大学、伊利诺伊大学厄本那-香槟分校和 DeepSeek AI 的作者提出 GDPO,一种用于多奖励强化学习的新颖策略优化方法,通过按目标解耦奖励归一化以保留细粒度的优势差异,克服了 GRPO 中的信号坍缩问题;该方法在工具调用、数学推理和编程任务中实现了更准确、更稳定且更具泛化能力的训练,显著提升了与多样化人类偏好的对齐效果。
主要贡献
- 语言模型的多奖励强化学习(RL)在对齐多样化人类偏好方面日益重要,但直接将组相对策略优化(GRPO)应用于多种异构奖励会导致奖励组合坍缩为相同的优劣势值,降低训练信号分辨率,引发训练不稳定甚至失败。
- 所提出的组奖励解耦归一化策略优化(GDPO)通过在每项独立奖励上分别进行组内归一化,保留各奖励维度间的相对差异,随后进行批量优势归一化,以维持与奖励数量无关的稳定更新幅度。
- GDPO 在三个任务——工具调用、数学推理和编程推理中均持续优于 GRPO,表现出更高的准确率(AIME 上最高提升 6.3%)、更好的格式合规性以及更优的训练稳定性,证明了其在多奖励 RL 中的有效性与泛化能力。
引言
随着语言模型能力的不断提升,使其与多样化的用户偏好(如准确性、安全性、连贯性及格式遵循)对齐变得愈发关键。这一目标正越来越多地通过多奖励强化学习(RL)实现,即利用多个奖励信号指导策略优化。然而,以往工作通常直接将组相对策略优化(GRPO)应用于奖励总和,由于组内归一化机制,不同奖励组合被压缩为相同的优劣势值,导致信号失真,降低训练精度,损害收敛性,甚至在涉及多目标的复杂任务中引发早期训练失败。
为解决此问题,作者提出组奖励解耦归一化策略优化(GDPO),在应用批量优势归一化前,对各独立奖励分别进行归一化处理。该方法保留了奖励组合间的细粒度差异,从而实现更准确、更稳定的策略更新。GDPO 在奖励数量变化时仍保持数值稳定性,避免了 GRPO 中固有的信号坍缩问题。
在工具调用、数学推理和代码生成任务上的评估表明,GDPO 在正确性和约束遵循性指标上均持续优于 GRPO。例如,在 AIME 数学基准测试中,其准确率最高提升 6.3%,同时生成更短、更简洁的响应。结果表明,GDPO 作为 GRPO 在多奖励 RL 中的一种稳健替代方案,具有显著的有效性与泛化能力。
方法
作者提出组奖励解耦归一化策略优化(GDPO),旨在解决使用组相对策略优化(GRPO)进行多奖励强化学习时出现的奖励坍缩问题。GDPO 的核心思想是通过将归一化过程解耦,对每一项独立奖励分别进行组内归一化,再将归一化后的奖励聚合为最终的优势信号。这与 GRPO 的做法形成对比:GRPO 先将所有奖励求和,再对总和进行组内归一化。
参见框架图 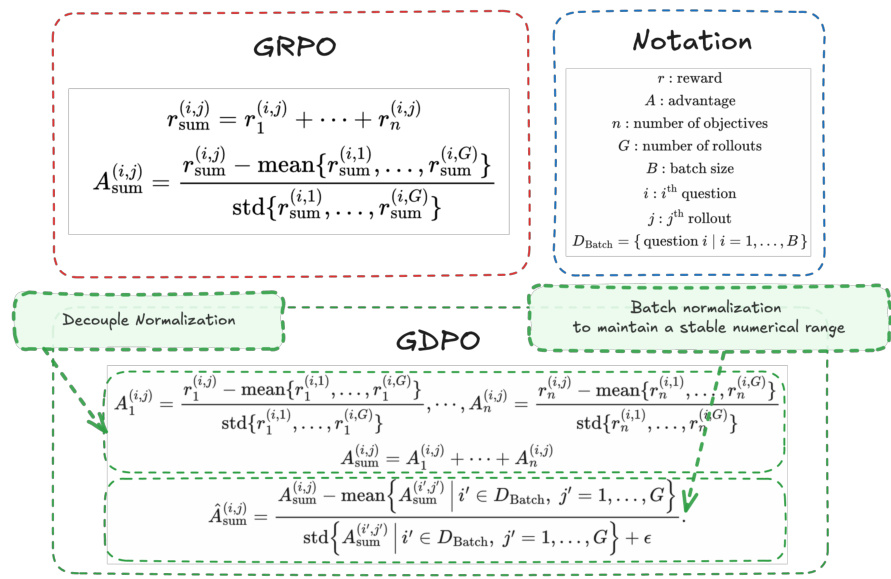 。如图所示,GRPO 框架通过将单个奖励 r1(i,j),…,rn(i,j) 求和,计算出总奖励 rsum(i,j)。随后,优势 Asum(i,j) 通过对相同问题的所有轨迹的总奖励进行归一化得到。相比之下,GDPO 首先对每项奖励 rk(i,j) 独立归一化,使用第 i 个问题在全部 G 条轨迹上的均值与标准差,得到归一化优势 Ak(i,j)。整体优势通过求和这些归一化优势获得:Asum(i,j)=∑k=1nAk(i,j)。该求和结果随后在整批数据上进行归一化,以确保数值范围稳定,最终得到优势 A^sum(i,j)。
。如图所示,GRPO 框架通过将单个奖励 r1(i,j),…,rn(i,j) 求和,计算出总奖励 rsum(i,j)。随后,优势 Asum(i,j) 通过对相同问题的所有轨迹的总奖励进行归一化得到。相比之下,GDPO 首先对每项奖励 rk(i,j) 独立归一化,使用第 i 个问题在全部 G 条轨迹上的均值与标准差,得到归一化优势 Ak(i,j)。整体优势通过求和这些归一化优势获得:Asum(i,j)=∑k=1nAk(i,j)。该求和结果随后在整批数据上进行归一化,以确保数值范围稳定,最终得到优势 A^sum(i,j)。
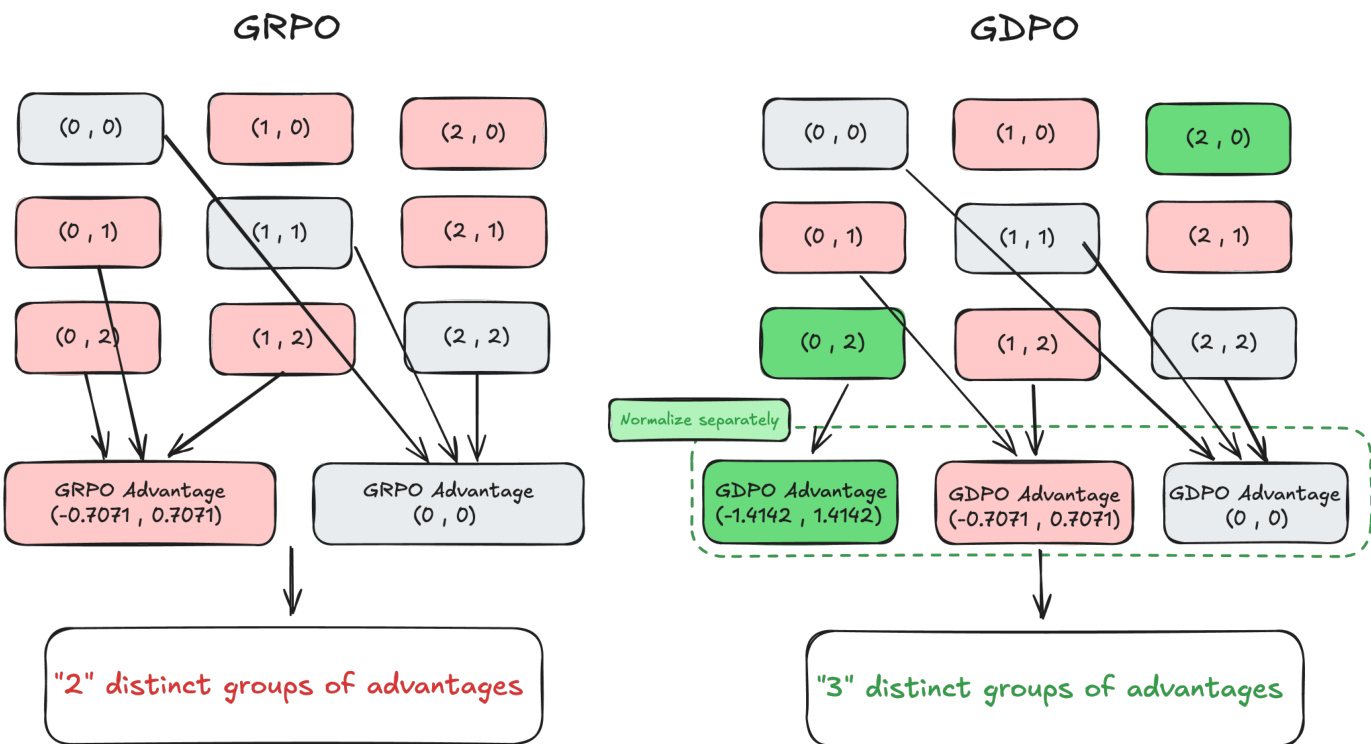 如图所示,这种解耦方法可防止 GRPO 中的信息丢失。在 GRPO 框架中,不同的奖励组合(如 (0,2) 和 (0,1))可能被归一化为相同的优劣势值,导致不同奖励信号坍缩为同一组。例如,(0,2) 和 (0,1) 均映射为相同的 GRPO 优势值 (−0.7071,0.7071),仅形成两个不同的优势组。而 GDPO 对每个奖励维度独立归一化,保留了这些组合间的差异。例如,(0,1) 变为 (−0.7071,0.7071),(0,2) 变为 (−1.4142,1.4142),从而形成三个不同的优势组。这使得 GDPO 能提供更具表现力和准确性的训练信号,更真实地反映奖励组合间的相对差异。
如图所示,这种解耦方法可防止 GRPO 中的信息丢失。在 GRPO 框架中,不同的奖励组合(如 (0,2) 和 (0,1))可能被归一化为相同的优劣势值,导致不同奖励信号坍缩为同一组。例如,(0,2) 和 (0,1) 均映射为相同的 GRPO 优势值 (−0.7071,0.7071),仅形成两个不同的优势组。而 GDPO 对每个奖励维度独立归一化,保留了这些组合间的差异。例如,(0,1) 变为 (−0.7071,0.7071),(0,2) 变为 (−1.4142,1.4142),从而形成三个不同的优势组。这使得 GDPO 能提供更具表现力和准确性的训练信号,更真实地反映奖励组合间的相对差异。
实验
- 在工具调用任务上对比 GDPO 与 GRPO(第 4.1 节):对于 Qwen2.5-1.5B 模型,GDPO 在 BFCL-v3 上平均准确率高出 2.7%,格式正确率提升超过 4%,在五次运行中均稳定收敛至更高的正确率与格式奖励。
- 对 GRPO 是否使用标准差归一化的消融研究:GRPO 无标准差归一化虽在正确率上达到相近增益,但在格式奖励上无法收敛,BFCL-v3 上格式正确率仅为 0%,表明多奖励优化中存在不稳定性。
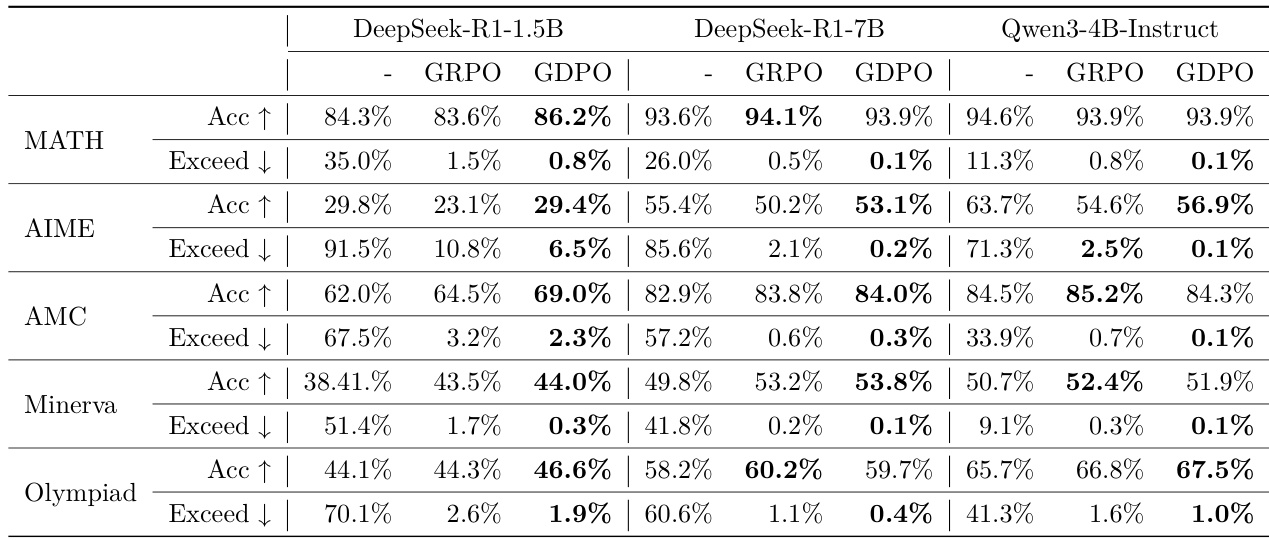
- 在数学推理任务上对比 GDPO 与 GRPO(第 4.2 节):GDPO 在 MATH 上 pass@1 准确率最高提升 6.7%,在 AIME 上提升 3%,同时将长度超限比例降至 0.1–0.2%(GRPO 为 2.1–2.5%),展现出在准确率与效率之间更优的权衡。
- 分析奖励权重与条件奖励的影响:单独降低长度奖励权重效果有限;将长度奖励与正确性条件化后显著提升对齐效果,GDPO 在 AIME 上准确率比 GRPO 高 4.4%,长度违规率降低 16.9%。
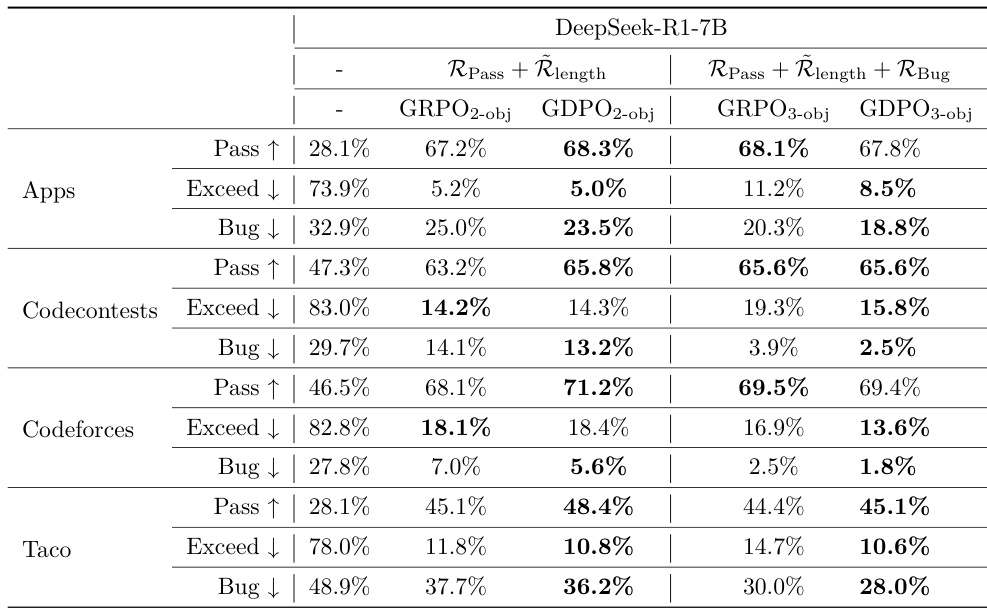
- 扩展至三奖励编程推理任务(第 4.3 节):GDPO 在 Codecontests 和 Taco 上 pass 率提升 2.6–3.3%,长度违规增加极少,同时降低 bug 比例并维持 pass 率,展现出对三目标任务的强大泛化能力。
作者在数学推理任务(优化准确率与长度约束)上对比 GDPO 与 GRPO,发现 GDPO 始终实现更高准确率并更好遵守长度限制。尽管两者初期均优先优化较简单的长度奖励,但 GDPO 能更有效地恢复并提升正确率,从而在所有基准测试中表现更优。

作者在包含三个奖励目标(通过率、长度约束、bug 比例)的编程推理任务上对比 GDPO 与 GRPO,结果表明 GDPO 在所有目标上均保持更优平衡,维持相近通过率的同时显著降低长度超限比例与 bug 比例。
结果表明,GDPO 在所有数学推理基准测试中均持续优于 GRPO,实现更高准确率并显著降低长度超限比例。在 AIME 和奥数等高难度任务上,GDPO 准确率最高提升 3%,同时将长度违规降至接近零。
作者使用 GDPO 优化工具调用任务中的两个奖励——调用正确性与格式合规性,结果表明 GDPO 在五次训练运行中均持续获得更高的正确率与格式奖励,优于 GRPO。在下游 BFCL-v3 基准测试中,GDPO 将平均工具调用准确率和格式正确率分别提升最多 5% 和 4%。

作者使用 GDPO 优化工具调用任务中的两个奖励——调用正确性与格式合规性,结果表明 GDPO 在五次训练运行中均持续获得更高的正确率与格式奖励,优于 GRPO。在下游 BFCL-v3 基准测试中,GDPO 将平均工具调用准确率和格式正确率分别提升最多 5% 和 4%。