Command Palette
Search for a command to run...
Qwen3 Technical Report
Qwen3 Technical Report
Abstract
In this work, we present Qwen3, the latest version of the Qwen model family. Qwen3 comprises a series of large language models (LLMs) designed to advance performance, efficiency, and multilingual capabilities. The Qwen3 series includes models of both dense and Mixture-of-Expert (MoE) architectures, with parameter scales ranging from 0.6 to 235 billion. A key innovation in Qwen3 is the integration of thinking mode (for complex, multi-step reasoning) and non-thinking mode (for rapid, context-driven responses) into a unified framework. This eliminates the need to switch between different models--such as chat-optimized models (e.g., GPT-4o) and dedicated reasoning models (e.g., QwQ-32B)--and enables dynamic mode switching based on user queries or chat templates. Meanwhile, Qwen3 introduces a thinking budget mechanism, allowing users to allocate computational resources adaptively during inference, thereby balancing latency and performance based on task complexity. Moreover, by leveraging the knowledge from the flagship models, we significantly reduce the computational resources required to build smaller-scale models, while ensuring their highly competitive performance. Empirical evaluations demonstrate that Qwen3 achieves state-of-the-art results across diverse benchmarks, including tasks in code generation, mathematical reasoning, agent tasks, etc., competitive against larger MoE models and proprietary models. Compared to its predecessor Qwen2.5, Qwen3 expands multilingual support from 29 to 119 languages and dialects, enhancing global accessibility through improved cross-lingual understanding and generation capabilities. To facilitate reproducibility and community-driven research and development, all Qwen3 models are publicly accessible under Apache 2.0.
One-sentence Summary
The authors propose Qwen3, a unified large language model family with dense and Mixture-of-Expert architectures spanning 0.6 to 235 billion parameters, integrating dynamic thinking and non-thinking modes for adaptive reasoning and response efficiency, enabling seamless task-specific inference without model switching, while introducing a thinking budget mechanism for resource optimization and significantly expanding multilingual support to 119 languages, with publicly available models under Apache 2.0.
Key Contributions
- Qwen3 introduces a unified architecture that seamlessly integrates thinking mode for complex, multi-step reasoning and non-thinking mode for fast, context-driven responses, eliminating the need to switch between separate models and enabling dynamic adaptation based on task demands.
- The model leverages a 36-trillion-token pre-training dataset spanning 119 languages and dialects, with a three-stage training process that enhances reasoning, coding, and long-context understanding, while a thinking budget mechanism allows users to control computational resources per task.
- Qwen3 achieves state-of-the-art performance on key benchmarks—including 85.7 on AIME'24, 70.7 on LiveCodeBench v5, and 2,056 on CodeForces—demonstrating strong competitiveness against larger proprietary and MoE models, especially in code generation, mathematical reasoning, and agent tasks.
Introduction
The authors leverage the growing momentum in open-source large language models to advance the pursuit of artificial general intelligence, addressing the limitations of prior models that often required separate architectures for reasoning and non-reasoning tasks, lacked fine-grained control over computational effort, and suffered from restricted multilingual and long-context capabilities. To overcome these challenges, Qwen3 introduces a unified architecture that seamlessly integrates thinking and non-thinking modes within a single model, enabling dynamic adjustment of reasoning depth via configurable thinking budgets. This design, combined with pre-training on 36 trillion tokens across 119 languages and a multi-stage post-training pipeline incorporating chain-of-thought supervision and reinforcement learning, allows Qwen3 to achieve state-of-the-art performance in coding, mathematics, and agent-based tasks. The release of both dense and Mixture-of-Experts variants—up to 235 billion total parameters with 22 billion activated per token—ensures scalability and efficiency, making Qwen3 a powerful, flexible, and accessible foundation for diverse real-world applications.
Dataset
- The pre-training dataset comprises 36 trillion tokens across 119 languages and dialects, more than triple the linguistic coverage of Qwen2.5, which used 29 languages.
- Data sources include high-quality content from diverse domains such as coding, STEM, reasoning tasks, books, multilingual texts, and synthetic data.
- Additional text was extracted from PDF-like documents using the Qwen2.5-VL model for optical character recognition, followed by quality refinement via the Qwen2.5 model.
- Trillions of synthetic tokens were generated using Qwen2.5, Qwen2.5-Math, and Qwen2.5-Coder models, producing structured content like textbooks, instructions, question-answering pairs, and code snippets across dozens of domains.
- A multilingual data annotation system labeled over 30 trillion tokens with fine-grained metadata on educational value, domain, field, and safety, enabling precise data filtering and mixture optimization.
- Unlike prior approaches that adjust data mixtures at the source or domain level, this work optimizes the mixture at the instance level using ablation studies on small proxy models with detailed labels.
- For long Chain-of-Thought (long-CoT) training, a specialized dataset was curated for math, code, logical reasoning, and general STEM problems, each paired with verified answers or test cases.
- A two-phase filtering process was applied: first, queries were filtered using Qwen2.5-72B-Instruct to exclude non-verifiable, multi-part, or easily answerable questions, ensuring only complex reasoning tasks remained.
- Queries were annotated by Qwen2.5-72B-Instruct for domain classification to maintain balanced representation across categories.
- For each filtered query, N candidate responses were generated using QwQ-32B; if no correct solution was found, human annotators evaluated accuracy.
- Responses were further filtered to remove those with incorrect final answers, excessive repetition, guesswork, reasoning-summary inconsistencies, language/style shifts, or potential overlap with the validation set.
- The final refined dataset was used for a minimal cold-start training phase with limited samples and training steps, aiming to instill foundational reasoning patterns without overfitting to performance metrics.
- This preparatory phase sets the stage for subsequent reinforcement learning, preserving model flexibility and enabling broader improvement.
Method
The Qwen3 series employs a comprehensive training framework designed to achieve high performance across diverse tasks while enabling efficient deployment. The post-training pipeline, illustrated in the figure below, is structured around two primary objectives: thinking control and strong-to-weak distillation. For flagship models, the process follows a four-stage training sequence. The first stage, Long-CoT Cold Start, initializes the model with a focus on long-context understanding. This is followed by Stage 2, Reasoning RL, which enhances the model's reasoning capabilities through reinforcement learning. Stage 3, Thinking Mode Fusion, integrates non-thinking and thinking modes into a unified framework, allowing dynamic mode switching based on user input. Finally, Stage 4, General RL, broadens the model's capabilities across various scenarios by refining instruction following, format adherence, preference alignment, agent ability, and specialized scenario performance.
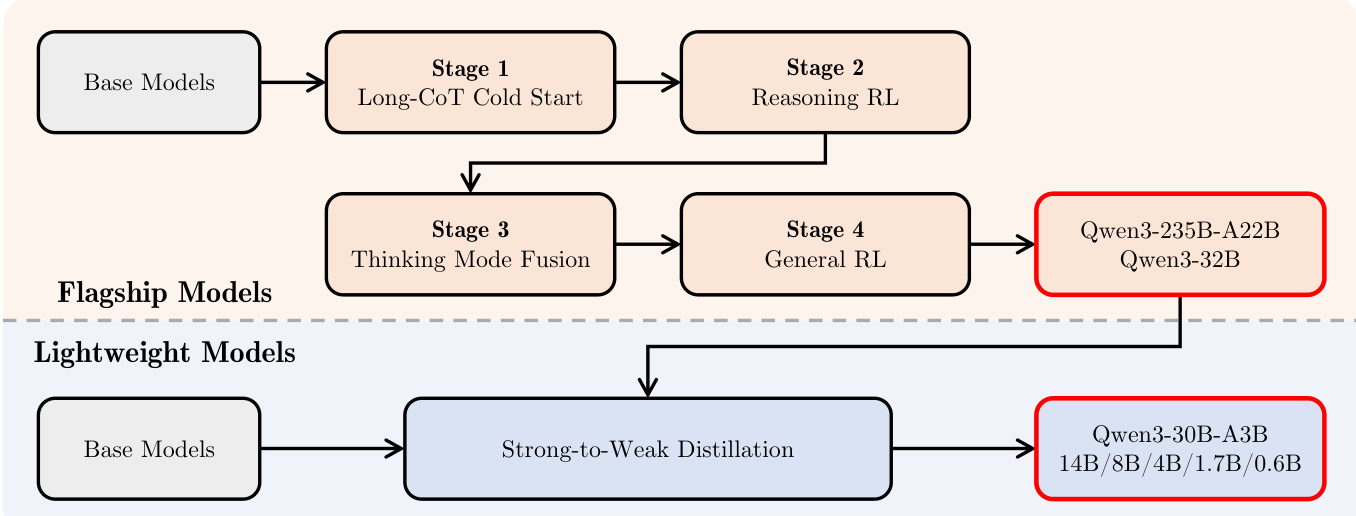
The integration of thinking and non-thinking modes is achieved through a carefully designed chat template. Users can specify the desired mode by including /think or /no_think flags in the query or system message. This enables the model to dynamically switch between modes, with the model defaulting to thinking mode unless explicitly instructed otherwise. For non-thinking mode, an empty thinking block is retained in the assistant's response to maintain internal format consistency. This design allows developers to control the model's reasoning behavior by simply modifying the chat template.
The framework also incorporates a thinking budget mechanism, which allows users to allocate computational resources adaptively during inference. When the model's thinking process reaches a user-defined threshold, the thinking is manually halted, and a stop-thinking instruction is inserted. The model then generates a final response based on its accumulated reasoning up to that point. This capability emerges naturally from the Thinking Mode Fusion stage and enables a balance between latency and performance based on task complexity.
For lightweight models, the Strong-to-Weak Distillation approach streamlines the training process. This pipeline consists of two phases: off-policy distillation and on-policy distillation. In the off-policy phase, the outputs of teacher models generated with both thinking and non-thinking modes are used to distill knowledge into the student model, enabling it to develop basic reasoning skills and mode-switching capabilities. In the on-policy phase, the student model generates sequences in either mode, and is fine-tuned by aligning its logits with those of a teacher model to minimize the KL divergence. This approach significantly reduces the computational resources required to build smaller-scale models while ensuring their competitive performance.
Experiment
- Qwen3-235B-A22B-Base outperforms Qwen2.5-Plus-Base, Llama-4-Maverick-Base, and DeepSeek-V3-Base on 14 out of 15 benchmarks with only about 1/3 total parameters and 2/3 activated parameters, demonstrating superior efficiency and performance.
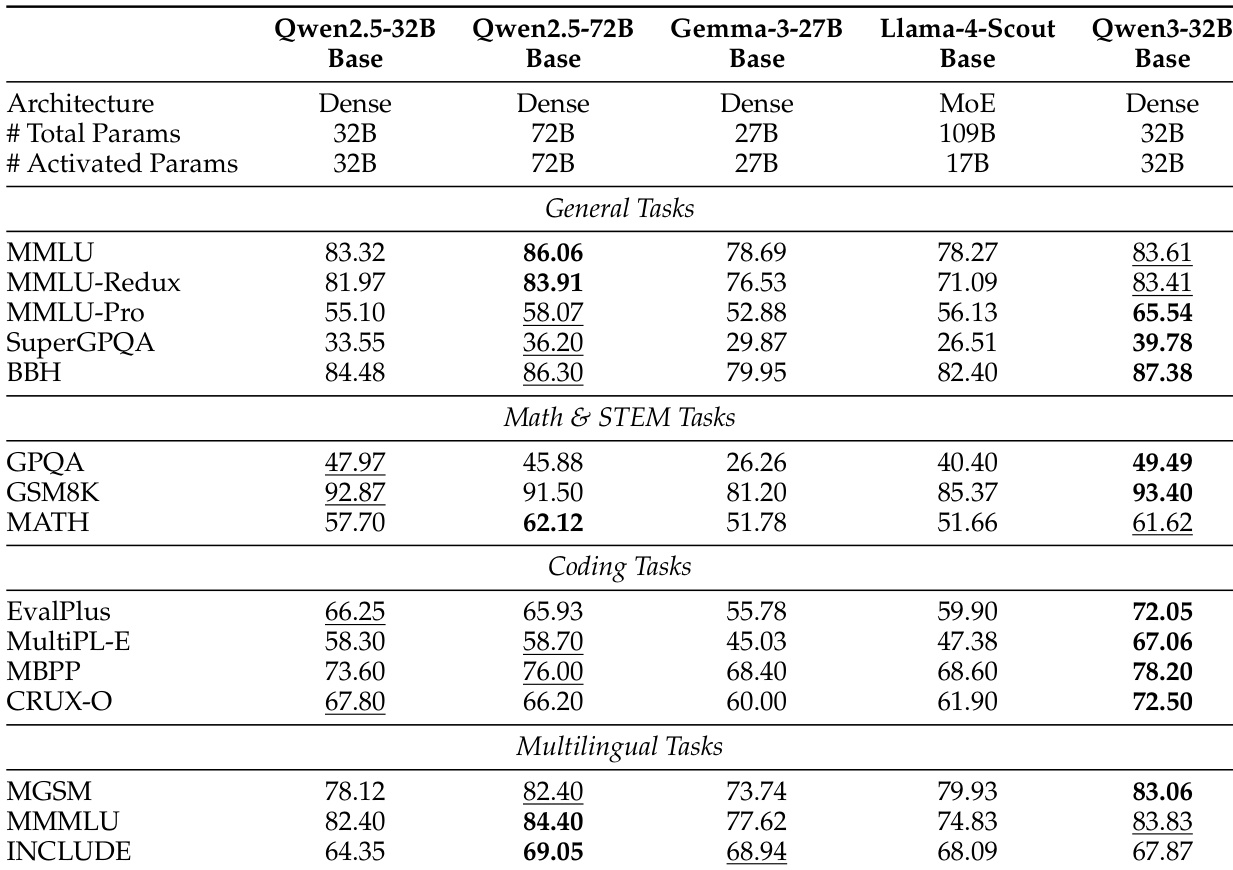
- Qwen3-32B-Base achieves 65.54 on MMLU-Pro and 39.78 on SuperGPQA, surpassing Qwen2.5-32B-Base and Gemma-3-27B-Base, and outperforms Qwen2.5-72B-Base on 10 of 15 benchmarks despite having less than half the parameters.
- Qwen3-30B-A3B-Base achieves comparable performance to Qwen3-14B-Base and Qwen2.5-32B-Base with only 1/5 activated parameters, highlighting the effectiveness of Strong-to-Weak Distillation.
- Qwen3-235B-A22B (Thinking) achieves state-of-the-art results among open-source models, outperforming DeepSeek-R1 on 17/23 benchmarks and approaching closed-source models like OpenAI-o1 and Gemini2.5-Pro.
- Qwen3-235B-A22B (Non-thinking) surpasses GPT-4o-2024-11-20 on 18/23 benchmarks, demonstrating strong general capabilities without explicit reasoning.
- Qwen3-32B (Thinking) outperforms QwQ-32B on 17/23 benchmarks and competes with OpenAI-o3-mini (medium), establishing itself as a new state-of-the-art 32B reasoning model.
- Qwen3-8B, Qwen3-4B, Qwen3-1.7B, and Qwen3-0.6B models outperform larger Qwen2.5 counterparts in both thinking and non-thinking modes, confirming the success of distillation for lightweight models.
- On the RULER benchmark, Qwen3 models show strong long-context performance in non-thinking mode, though slight degradation occurs in thinking mode due to interference from reasoning content.
- On Belebele and multilingual benchmarks, Qwen3 models achieve competitive performance across 80 languages, outperforming Qwen2.5 and matching similarly-sized Gemma models.
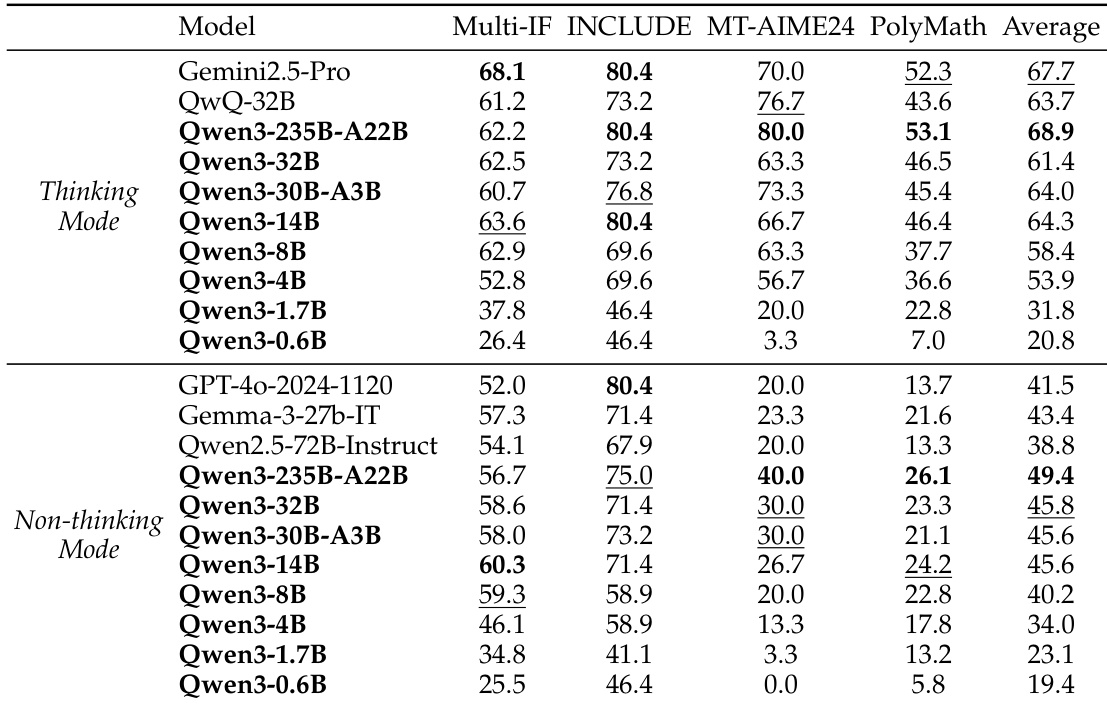
The authors use the table to compare the performance of Qwen3 models in thinking and non-thinking modes across multiple benchmarks. Results show that Qwen3-235B-A22B achieves the highest average score in thinking mode, outperforming Gemini2.5-Pro and other strong baselines, while Qwen3-32B and Qwen3-30B-A3B also demonstrate strong performance in both modes, surpassing models with larger parameter counts.
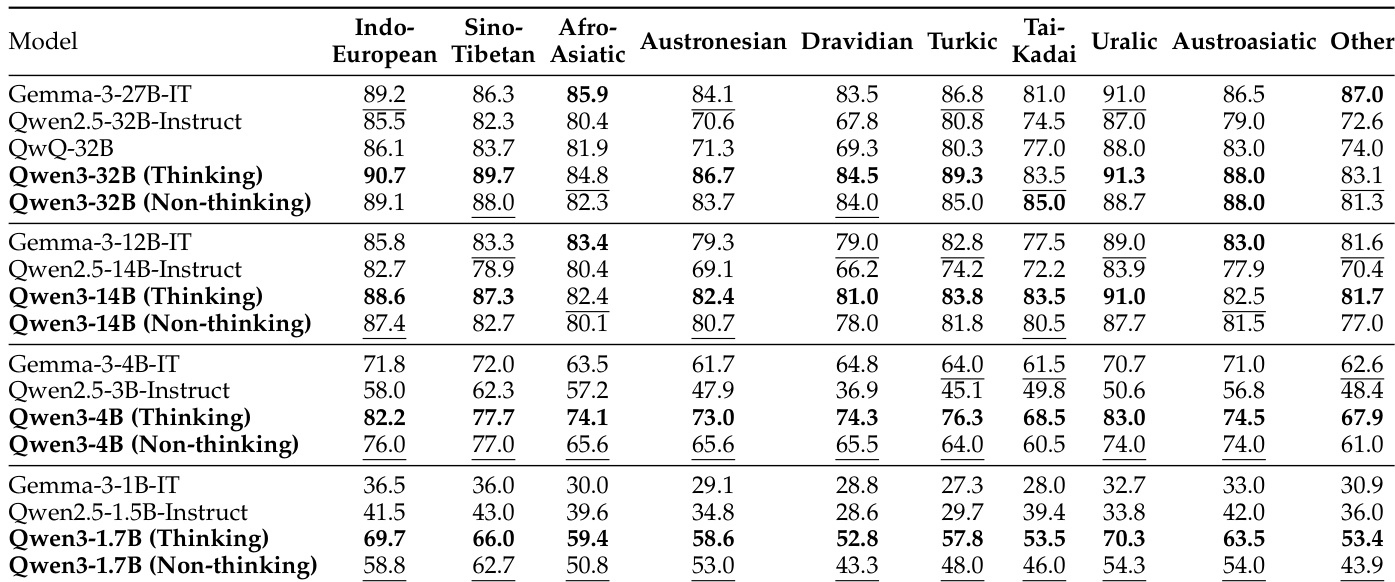
The authors compare the multilingual performance of Qwen3 models across various languages, including Indo-European, Sino-Tibetan, Afro-Asiatic, and others. Results show that Qwen3-32B (Non-thinking) achieves the highest scores in most language categories, outperforming Qwen2.5 models of similar size and demonstrating strong multilingual capabilities.
The authors compare Qwen3-32B-Base with several open-source models of similar size, including Qwen2.5-32B-Base, Gemma-3-27B-Base, and Llama-4-Scout-Base. Results show that Qwen3-32B-Base outperforms Qwen2.5-32B-Base and Gemma-3-27B-Base on most benchmarks, achieves competitive results against the larger Qwen2.5-72B-Base, and significantly surpasses Llama-4-Scout-Base despite having only one-third of its parameters.
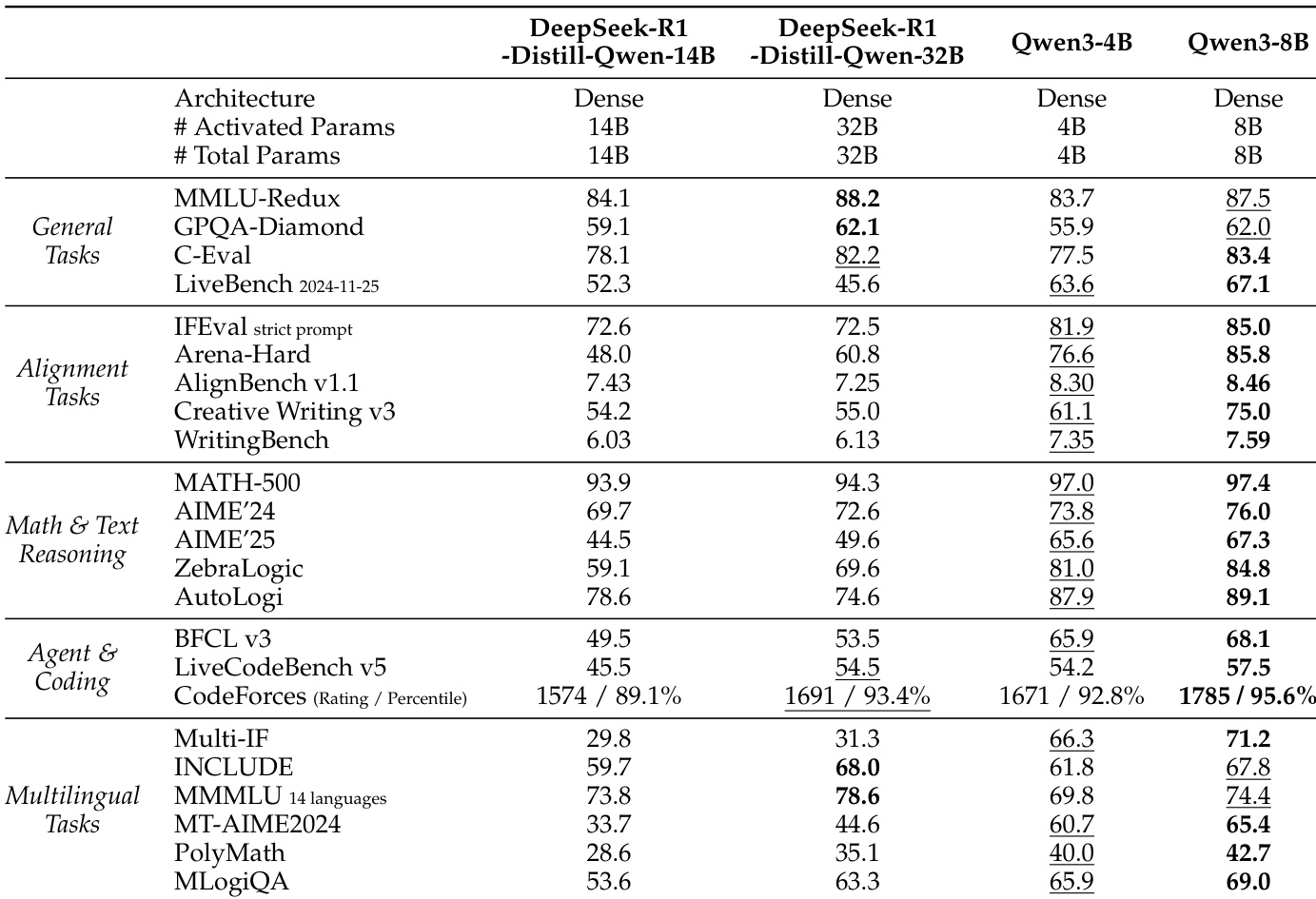
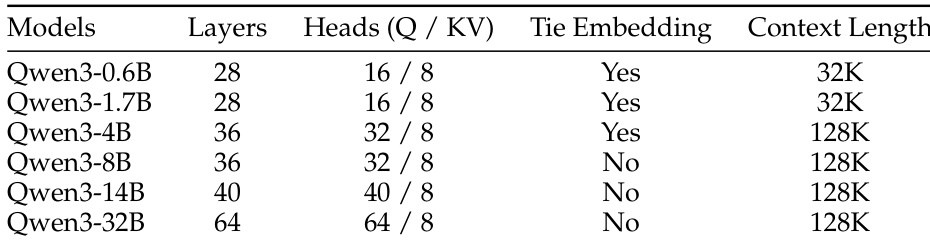
The authors use the provided table to detail the architectural specifications of the Qwen3 series models, showing that model size increases with layers, heads, and context length. The table indicates that Qwen3-0.6B and Qwen3-1.7B have tie embedding and 32K context length, while larger models from Qwen3-4B to Qwen3-32B use 128K context length and do not employ tie embedding.
The authors compare Qwen3-4B and Qwen3-8B with DeepSeek-R1-Distill models and other baselines across multiple tasks. Results show that Qwen3-8B outperforms Qwen3-4B and the DeepSeek-R1-Distill models in most benchmarks, particularly in math, reasoning, and coding tasks, while also achieving higher scores than larger models like DeepSeek-R1-Distill-Qwen-32B in several areas.