Command Palette
Search for a command to run...
PUSA V1.0: Surpassing Wan-I2V with $500 Training Cost by Vectorized Timestep Adaptation
PUSA V1.0: Surpassing Wan-I2V with $500 Training Cost by Vectorized Timestep Adaptation
Abstract
The rapid advancement of video diffusion models has been hindered by fundamental limitations in temporal modeling, particularly the rigid synchronization of frame evolution imposed by conventional scalar timestep variables. While task-specific adaptations and autoregressive models have sought to address these challenges, they remain constrained by computational inefficiency, catastrophic forgetting, or narrow applicability. In this work, we present Pusa, a groundbreaking paradigm that leverages vectorized timestep adaptation (VTA) to enable fine-grained temporal control within a unified video diffusion framework. Besides, VTA is a non-destructive adaptation, which means it fully preserves the capabilities of the base model. By finetuning the SOTA Wan2.1-T2V-14B model with VTA, we achieve unprecedented efficiency -- surpassing the performance of Wan-I2V-14B with leq 1/200 of the training cost (500vs.geq100,000) and leq 1/2500 of the dataset size (4K vs. geq 10M samples). Pusa not only sets a new standard for image-to-video (I2V) generation, achieving a VBench-I2V total score of 87.32% (vs. 86.86% of Wan-I2V-14B), but also unlocks many zero-shot multi-task capabilities such as start-end frames and video extension -- all without task-specific training. Meanwhile, Pusa can still perform text-to-video generation. Mechanistic analyses reveal that our approach preserves the foundation model's generative priors while surgically injecting temporal dynamics, avoiding the combinatorial explosion inherent to vectorized timesteps. This work establishes a scalable, efficient, and versatile paradigm for next-generation video synthesis, democratizing high-fidelity video generation for research and industry alike. Code is open-sourced at https://github.com/Yaofang-Liu/Pusa-VidGen
One-sentence Summary
The authors, affiliated with City University of Hong Kong, Huawei Research, Tencent PCG, and other institutions, propose Pusa, a unified video diffusion framework leveraging vectorized timestep adaptation (VTA) to enable fine-grained temporal control without sacrificing base model capabilities. Unlike prior methods constrained by rigid timesteps or task-specific training, Pusa achieves SOTA image-to-video performance with 2500× less data and 200× lower training cost, while supporting zero-shot multi-task generation including video extension and text-to-video, offering a scalable, efficient, and versatile solution for high-fidelity video synthesis.
Key Contributions
- Conventional video diffusion models rely on scalar timestep variables that enforce rigid, synchronized frame evolution, limiting their ability to model complex temporal dynamics in tasks like image-to-video (I2V) generation.
- The authors introduce Pusa, a novel framework based on vectorized timestep adaptation (VTA), which enables fine-grained, independent frame evolution while preserving the base model's generative priors through non-destructive adaptation.
- Pusa achieves state-of-the-art I2V performance (VBench-I2V score of 87.32%) with over 2500× less training data and 200× lower training cost than prior models, while also supporting zero-shot multi-task capabilities like video extension and start-end frame generation.
Introduction
The authors leverage vectorized timestep adaptation (VTA) to overcome a key limitation in video diffusion models: the rigid, synchronized evolution of frames governed by scalar timesteps. Conventional models struggle with tasks like image-to-video (I2V) generation and editing due to this inflexible temporal structure, while prior solutions—such as task-specific fine-tuning or autoregressive designs—suffer from high computational costs, catastrophic forgetting, or limited applicability. The authors’ main contribution is Pusa V1.0, a non-destructive adaptation of the SOTA Wan2.1-T2V-14B model that replaces scalar timesteps with vectorized ones, enabling independent frame evolution. This allows a single unified model to achieve state-of-the-art I2V performance with 2500× less data and 200× lower training cost (500vs.100,000), while also supporting zero-shot capabilities like start-end frame generation, video extension, and text-to-video—all without retraining. Mechanistic analysis confirms that Pusa preserves the base model’s generative priors through targeted modifications, avoiding combinatorial complexity and enabling scalable, efficient, and versatile video synthesis.
Method
The authors leverage a flow matching framework to develop the Pusa model, which is designed for video generation with fine-grained temporal control. The core methodology builds upon continuous normalizing flows, where the goal is to learn a time-dependent vector field vt(zt,t) that governs the transformation of data from a prior distribution to a target data distribution. This is achieved by training a neural network vθ(zt,t) to approximate a target vector field ut(zt∣z0,z1), which is derived from a specified probability path connecting a data sample z0 to a prior sample z1. For linear interpolation paths, the target vector field simplifies to a constant difference z1−z0, independent of the intermediate state zt and the scalar timestep t. The training objective is to minimize the expected squared Euclidean distance between the predicted and target vector fields.
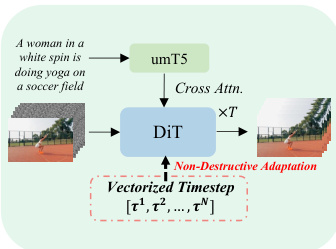
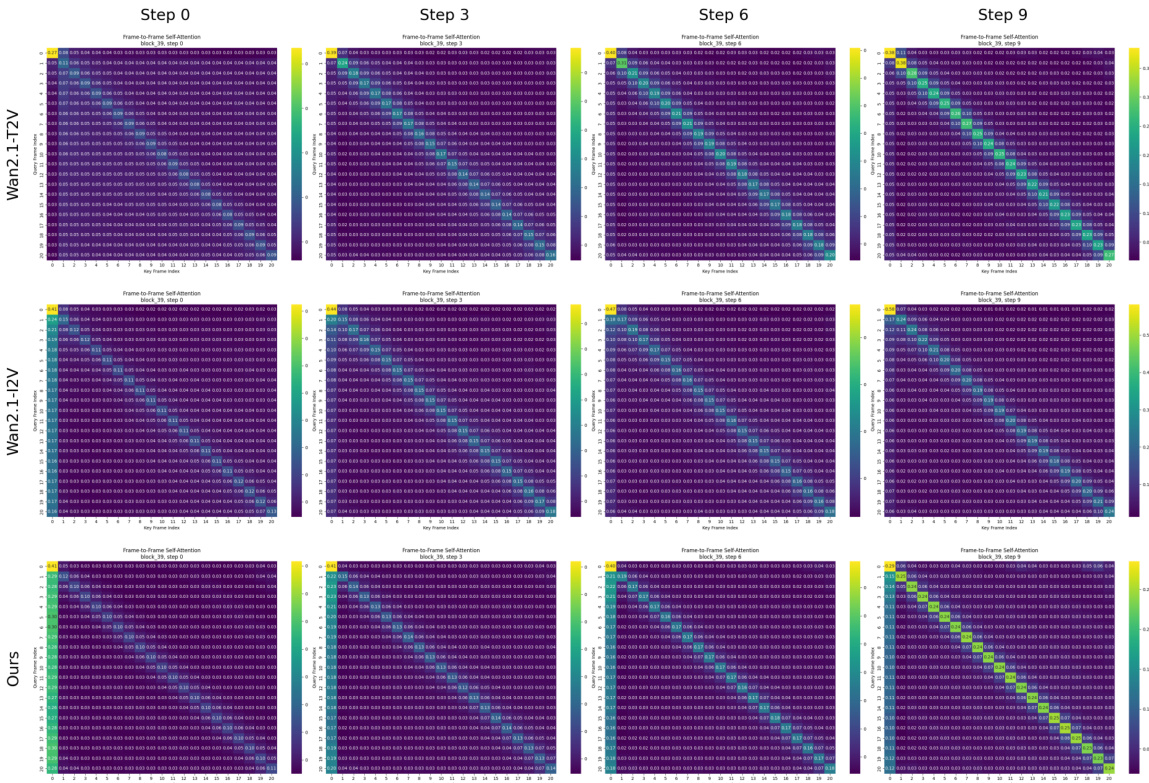
To extend this framework to video generation, the model introduces a vectorized timestep variable τ∈[0,1]N, where N is the number of frames in a video clip. This allows each frame to evolve along its own independent probability path, defined by a frame-specific progression parameter τi. The state of the video at a given vectorized timestep τ is constructed via frame-wise linear interpolation: Xτ=(1−τ)⊙X0+τ⊙X1. The target vector field for the entire video, U(X0,X1), is the difference between the prior and data videos, X1−X0, which remains constant across all timesteps. The model learns a single neural network vθ(X,τ) that predicts the velocity field for the entire video, conditioned on the current video state X and the vectorized timestep τ.
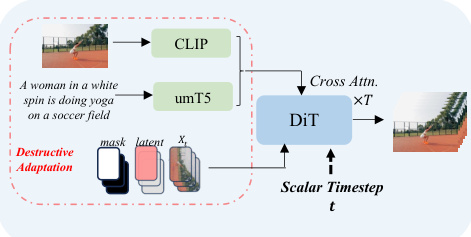
The Pusa model is implemented by adapting a pre-trained text-to-video (T2V) diffusion transformer, specifically a DiT (Diffusion Transformer) architecture. The key architectural modification, termed Vectorized Timestep Adaptation (VTA), re-engineers the model's temporal conditioning mechanism. Instead of processing a scalar timestep t, the model processes the vectorized timestep τ. This is achieved by modifying the timestep embedding module to generate a sequence of frame-specific embeddings Eτ. These embeddings are then projected to produce per-frame modulation parameters (scale, shift, and gate) for each block of the DiT architecture. This allows the model to condition the processing of each frame's latent representation zi on its individual timestep τi, enabling the model to handle a batch of frames at different points in their generative paths simultaneously. This adaptation is non-destructive, preserving the base model's T2V capabilities.
The training procedure optimizes the model parameters θ by minimizing the Frame-Aware Flow Matching (FAFM) objective function, which is a generalization of the standard flow matching loss to the vectorized timestep setting. The objective is to minimize the squared Frobenius norm of the difference between the predicted velocity field vθ(Xτ,τ) and the target field X1−X0. A key aspect of the training is the use of a Probabilistic Timestep Sampling Strategy (PTSS), which samples the vectorized timestep τ to expose the model to both synchronized and desynchronized frame evolutions. The authors employ a simplified training regimen with pasync=1, meaning each component of τ is sampled independently from a uniform distribution, which maximizes the diversity of temporal states the model encounters during training. This approach allows the model to learn fine-grained temporal control without the need for complex sampling strategies.
Experiment
- Industrial-Scale Efficiency: Pusa achieves unprecedented data efficiency (≤1/2500 of Wan-I2V's dataset size) and computational efficiency (≤1/200 of Wan-I2V's training cost) through lightweight LoRA fine-tuning on a large foundation model, enabling practical large-model adaptation.
- Multi-Task Generalization: Pusa supports zero-shot generation of diverse video tasks—including I2V, T2V, start-end frames, video extension, and completion—without additional training, enabled by flexible vectorized timestep conditioning.
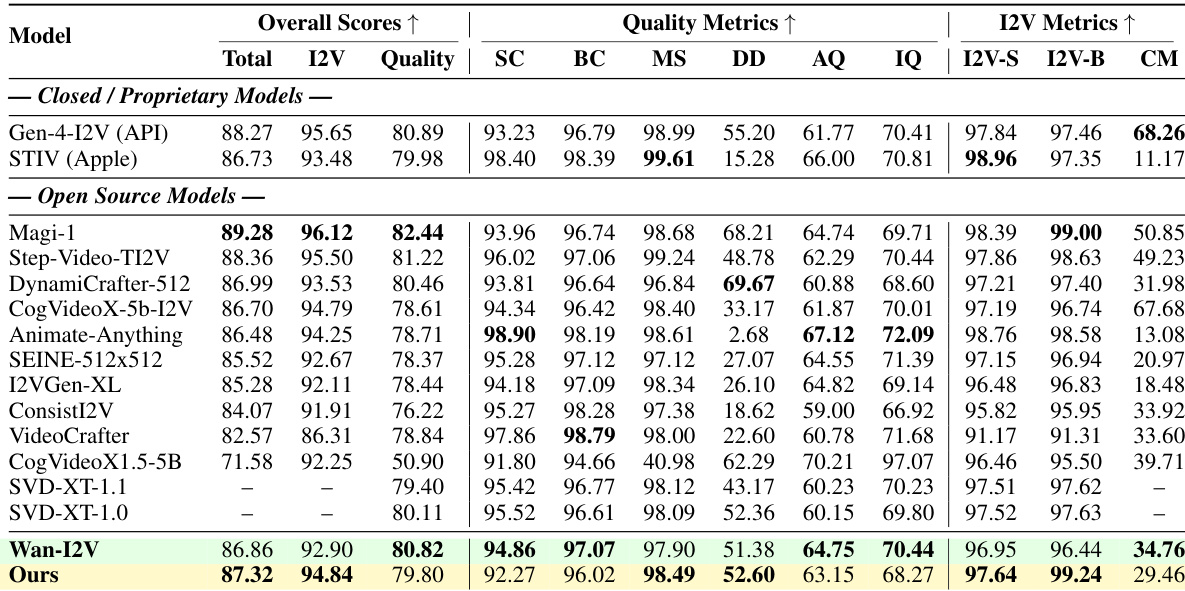
- Quality-Throughput Tradeoff: On Vbench-I2V, Pusa achieves a total score of 87.32%, surpassing Wan-I2V's 86.86%, with superior performance in subject consistency (97.64 vs. 96.95), background consistency (99.24 vs. 96.44), and dynamic motion (52.60 vs. 51.38), while using only 10 inference steps.
Results show that the model achieves optimal performance with a LoRA rank of 512 and an alpha of 1.7, as higher ranks consistently improve quality across metrics. The model converges rapidly, with peak performance reached at 900 training iterations, and further training leads to diminishing returns. Inference quality improves significantly up to 10 steps, after which gains become marginal, indicating that 10 steps provide the best balance between speed and output quality.
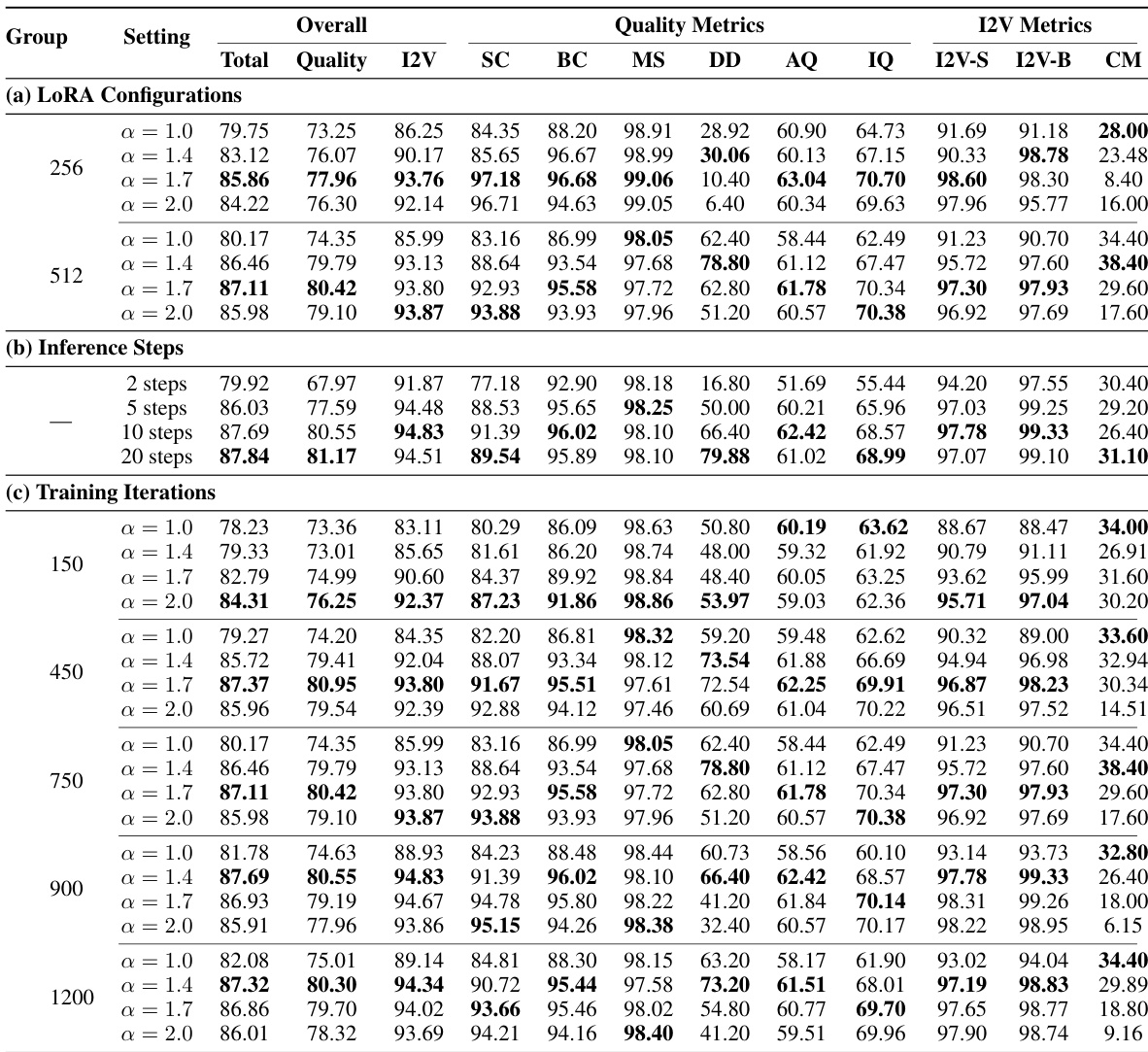
Results show that the proposed model achieves a total score of 87.32, surpassing the Wan-I2V baseline's 86.86, while using less than 1/2500th of the training data and 1/200th of the computational cost. The model demonstrates superior performance in key metrics, including I2V Background Consistency (99.24 vs. 96.44) and I2V Subject Consistency (97.64 vs. 96.95), indicating strong adherence to the input image condition.