Command Palette
Search for a command to run...
MMGR: Multi-Modal Generative Reasoning
MMGR: Multi-Modal Generative Reasoning
Abstract
Video foundation models generate visually realistic and temporally coherent content, but their reliability as world simulators depends on whether they capture physical, logical, and spatial constraints. Existing metrics such as Frechet Video Distance (FVD) emphasize perceptual quality and overlook reasoning failures, including violations of causality, physics, and global consistency. We introduce MMGR (Multi-Modal Generative Reasoning Evaluation and Benchmark), a principled evaluation framework based on five reasoning abilities: Physical, Logical, 3D Spatial, 2D Spatial, and Temporal. MMGR evaluates generative reasoning across three domains: Abstract Reasoning (ARC-AGI, Sudoku), Embodied Navigation (real-world 3D navigation and localization), and Physical Commonsense (sports and compositional interactions). MMGR applies fine-grained metrics that require holistic correctness across both video and image generation. We benchmark leading video models (Veo-3, Sora-2, Wan-2.2) and image models (Nano-banana, Nano-banana Pro, GPT-4o-image, Qwen-image), revealing strong performance gaps across domains. Models show moderate success on Physical Commonsense tasks but perform poorly on Abstract Reasoning (below 10 percent accuracy on ARC-AGI) and struggle with long-horizon spatial planning in embodied settings. Our analysis highlights key limitations in current models, including overreliance on perceptual data, weak global state consistency, and objectives that reward visual plausibility over causal correctness. MMGR offers a unified diagnostic benchmark and a path toward reasoning-aware generative world models.
One-sentence Summary
Researchers from University of Wisconsin–Madison, UCLA, Michigan State University, and et al. introduce MMGR, a benchmark evaluating five reasoning abilities (Physical, Logical, 3D/2D Spatial, Temporal) across Abstract Reasoning, Embodied Navigation, and Physical Commonsense domains. Unlike prior metrics focused on perceptual fidelity, MMGR reveals current video models like Veo-3 and Sora-2 achieve moderate physical commonsense performance but fail catastrophically on abstract reasoning (under 10% on ARC-AGI) and embodied navigation.
Key Contributions
- Current video generation models achieve high perceptual quality but lack evaluation for logical and physical reasoning capabilities, as traditional metrics like FVD and Inception Score prioritize appearance fidelity over semantic consistency and long-horizon coherence.
- The MMGR benchmark introduces a generative reasoning framework with novel tasks across three domains, including 2D Maze for spatial/logical/temporal reasoning, Sudoku for constraint satisfaction, and Panoramic View Navigation for embodied decision-making, adapting rigorous tests like ARC-AGI to probe world modeling.
- Evaluations on state-of-the-art models such as Veo-3 demonstrate successful execution in tasks like 3D Real-World Navigation and Simultaneous Localization and Generation, using datasets including Matterport3D and Habitat to validate capabilities in semantic grounding, trajectory planning, and coherent mental mapping.
Introduction
Video generation models have evolved from GANs to diffusion-based and transformer architectures, achieving high visual fidelity in systems like Sora and Veo. However, existing evaluation metrics prioritize perceptual quality and text alignment over logical coherence, failing to assess whether models internalize physical laws or execute consistent reasoning over time. Prior benchmarks also focus on discriminative understanding rather than generative reasoning capabilities. The authors address this gap by introducing the MMGR benchmark, which holistically evaluates five core reasoning abilities—Abstract Reasoning, Embodied Navigation, and Physical Commonsense—through tasks like 2D mazes, Sudoku, panoramic navigation, and physics-based video synthesis. This framework rigorously tests models' capacity to generate logically sound, physically plausible content beyond superficial realism.
Dataset
The authors use a benchmark comprising 1,853 evaluation samples across three domains and ten tasks, designed for fine-grained capability analysis. Key components include:
-
Abstract Reasoning (1,323 samples)
- Maze: 240 procedurally generated mazes (3×3 to 13×13 grids) using DFS and Wilson’s algorithms. Split into Easy (40), Medium (40), and Hard (40) per generator, with four start-goal configurations. Minimum path distance enforced; each maze has one solution.
- Sudoku: 300 puzzles (50 per difficulty/grid size). Includes 4×4 and 9×9 grids across Easy (many clues), Medium, and Hard (few clues) levels, ensuring unique solutions.
- ARC-AGI: 456 tasks (381 from v1, 75 from v2), classified by shape consistency (Match/Mismatch) and difficulty. Manually curated for unambiguous transformation rules.
- Visual Math: 327 problems aggregated from GSM8K, MATH500, AIME 2024/2025, and Omni-MATH, spanning grade school to Olympiad-level math.
-
Embodied Navigation (480 samples)
- Four tasks (120 samples each): 3D Real-World Navigation (Matterport3D/HM3D), Last-Mile Navigation (360° panoramas), Top-down View Navigation, and SLAG (cross-view alignment).
- Stratified across 24 configurations by environmental complexity (single/multi-floor), view fidelity (quality 3–5), trajectory distance (short/long), and goal specification (visual marker or language).
-
Physical Commonsense (50 samples)
- Physical Concepts: 25 samples from VideoPhy/VideoPhy v2, covering Solid-Solid (143 captions), Solid-Fluid (146), and Fluid-Fluid (55) interactions across statics/dynamics.
- Sports: 25 diverse examples from Ballet, Skiing, Diving, and Swimming, testing momentum, balance, and fluid dynamics.
- Balanced via stratification by interaction type, scenario context (controlled vs. sports), and complexity (Simple/Complex/Chain-Reaction).
The dataset is strictly for evaluation, with rigorous difficulty stratification and human verification. Processing includes:
- Maze/Sudoku: Algorithmic generation with controlled parameters (grid size, clues) and solution uniqueness checks.
- Embodied Navigation: Scene sourcing from Matterport3D, HM3D, and Habitat; goal specifications use red overlays or disambiguated language descriptions.
- Physical Commonsense: Random sampling from source corpora to ensure category/domain diversity.
No training splits or mixture ratios are applied, as the benchmark focuses exclusively on structured testing.
Method
The authors leverage a tripartite pipeline—Benchmark, Generation, and Evaluation—to systematically assess generative reasoning across abstract, embodied, and physical domains. The framework begins with the Benchmark module, which curates tasks organized into three domains: Abstract Reasoning (e.g., Maze, Sudoku, ARC-AGI), Embodied Navigation (e.g., 3D Real-World Navigation, Last-Mile Navigation), and Physical Commonsense (e.g., Sports, Physical Concept scenarios). Each domain is parameterized for granularity and hard-level control, enabling fine-grained analysis of model capabilities under varying structural and semantic constraints.
Refer to the framework diagram for an overview of the end-to-end workflow. The Generation module receives an input image and a natural-language prompt, then deploys either video generative models (Veo-3, Sora-2, Wan-2.2) to produce multi-frame trajectories or image generative models (Nano-Banana/Pro, GPT-4o-Image, Qwen-Image) to generate single-frame outputs. For instance, in the Maze task, a 7x7 grid is provided with start and end markers, and the model is prompted to generate a 2D animation that solves the maze. The output consists of sequential frames depicting the agent’s path from start to end.
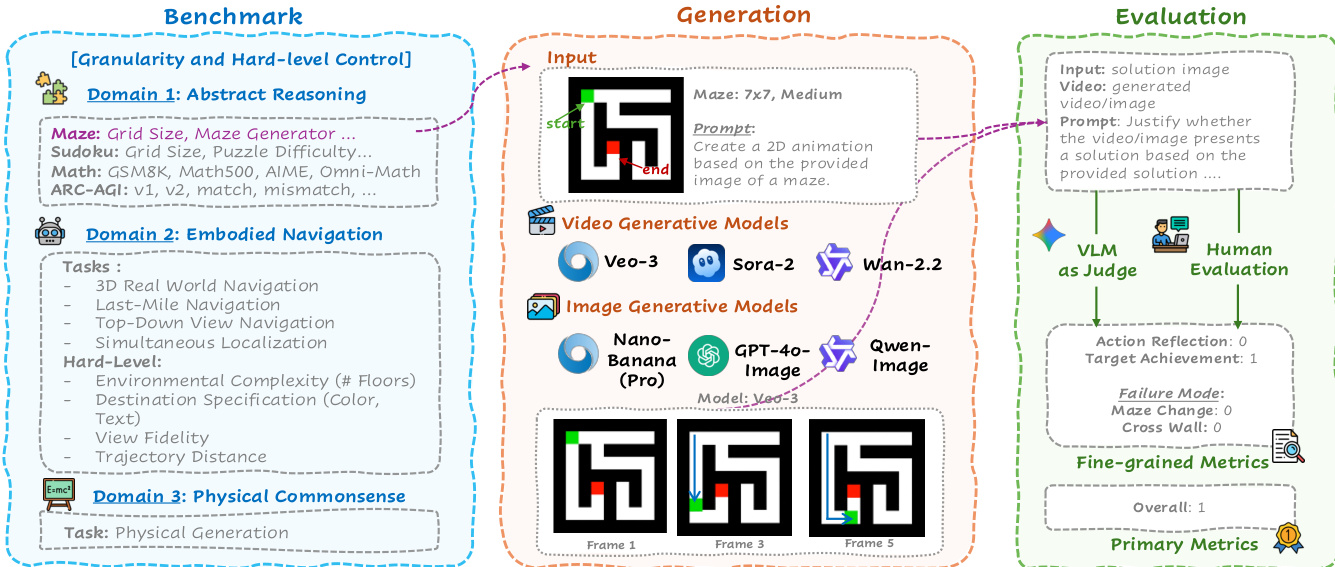
The Evaluation module employs a dual-path assessment: automated scoring via a VLM-based judge (Gemini-2.5-Pro) and, for a curated subset, human evaluation. The VLM evaluates the generated video or image against a solution image using structured criteria, including Action Reflection (0/1), Target Achievement (0/1), and Failure Mode flags (e.g., Maze Change, Cross Wall). These are aggregated into Fine-grained Metrics and a Primary Metric (Overall score), which reflects holistic success. The evaluation is designed to probe not just perceptual fidelity but the underlying reasoning—whether the output adheres to logical, spatial, and physical constraints implied by the prompt and input. This enables a domain-sensitive diagnosis of model strengths and weaknesses across the five core reasoning pillars: Physical, Logical, 3D Spatial, 2D Spatial, and Temporal Reasoning.
Experiment
- Evaluated MMGR benchmark across Abstract Reasoning, Embodied Navigation, and Physical Commonsense domains to assess five core reasoning abilities
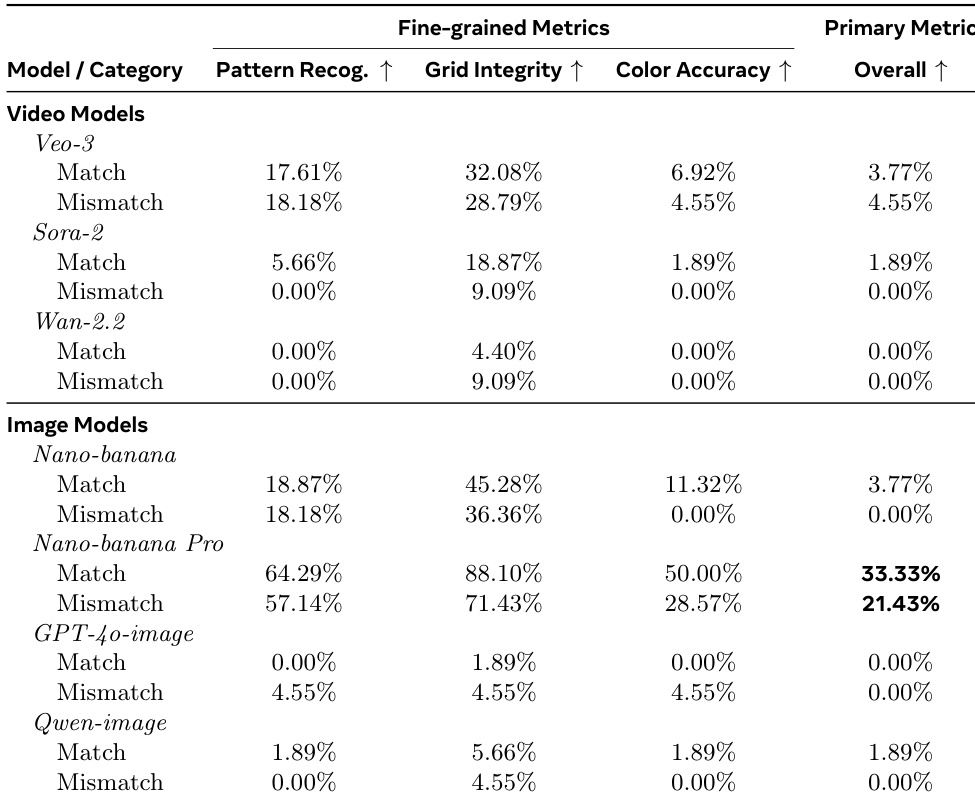
- On ARC-AGI v1, Nano-banana Pro achieved 30.54% accuracy, surpassing Sora-2 (20.18%) and revealing video models' temporal inconsistency in preserving static demonstrations
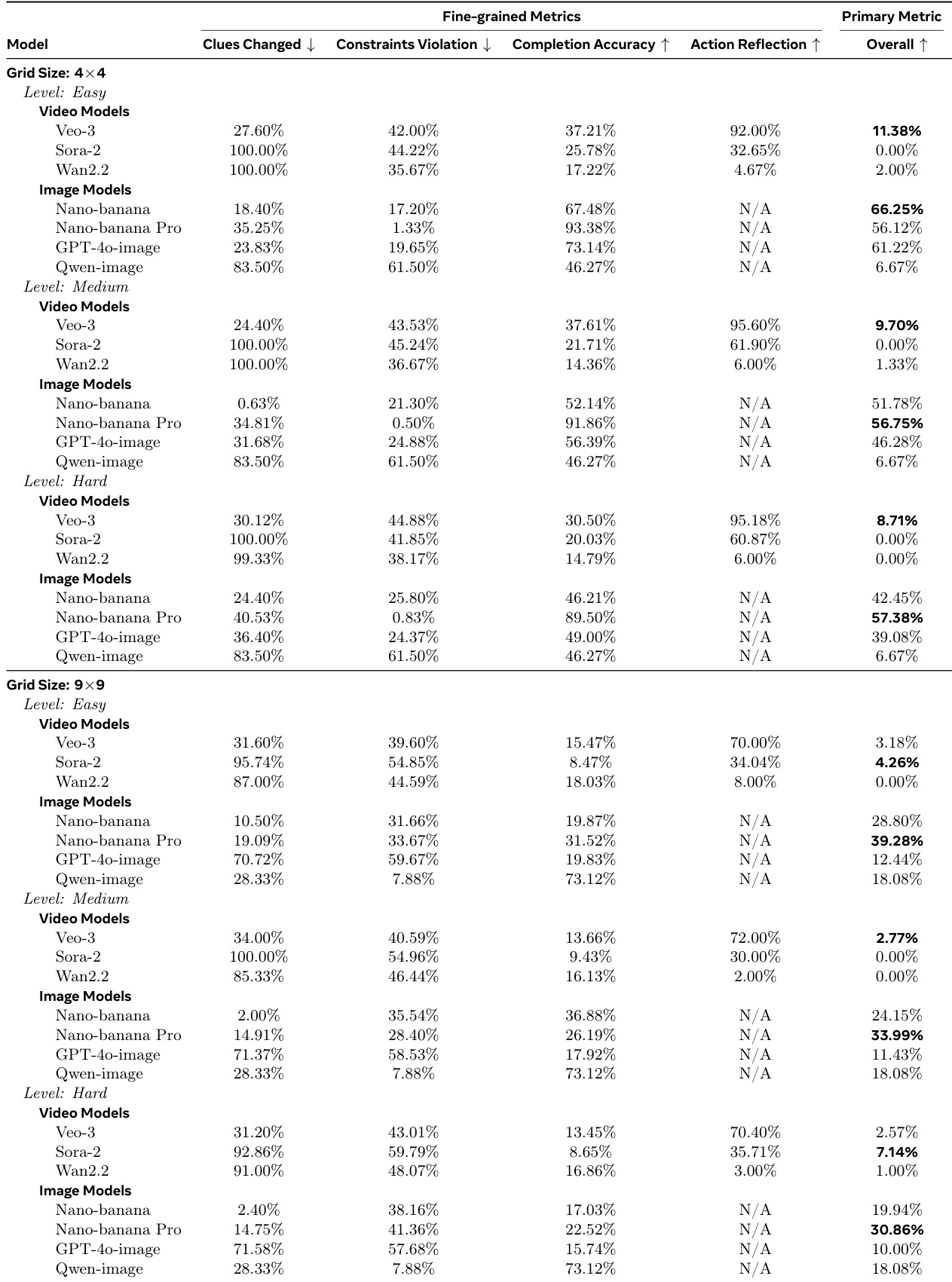
- In Sudoku tasks, image models significantly outperformed video models with Nano-banana Pro reaching 39.28% overall accuracy versus Veo-3's 11.38% on 4x4 Easy puzzles, with human evaluation showing 0% success for Veo-3
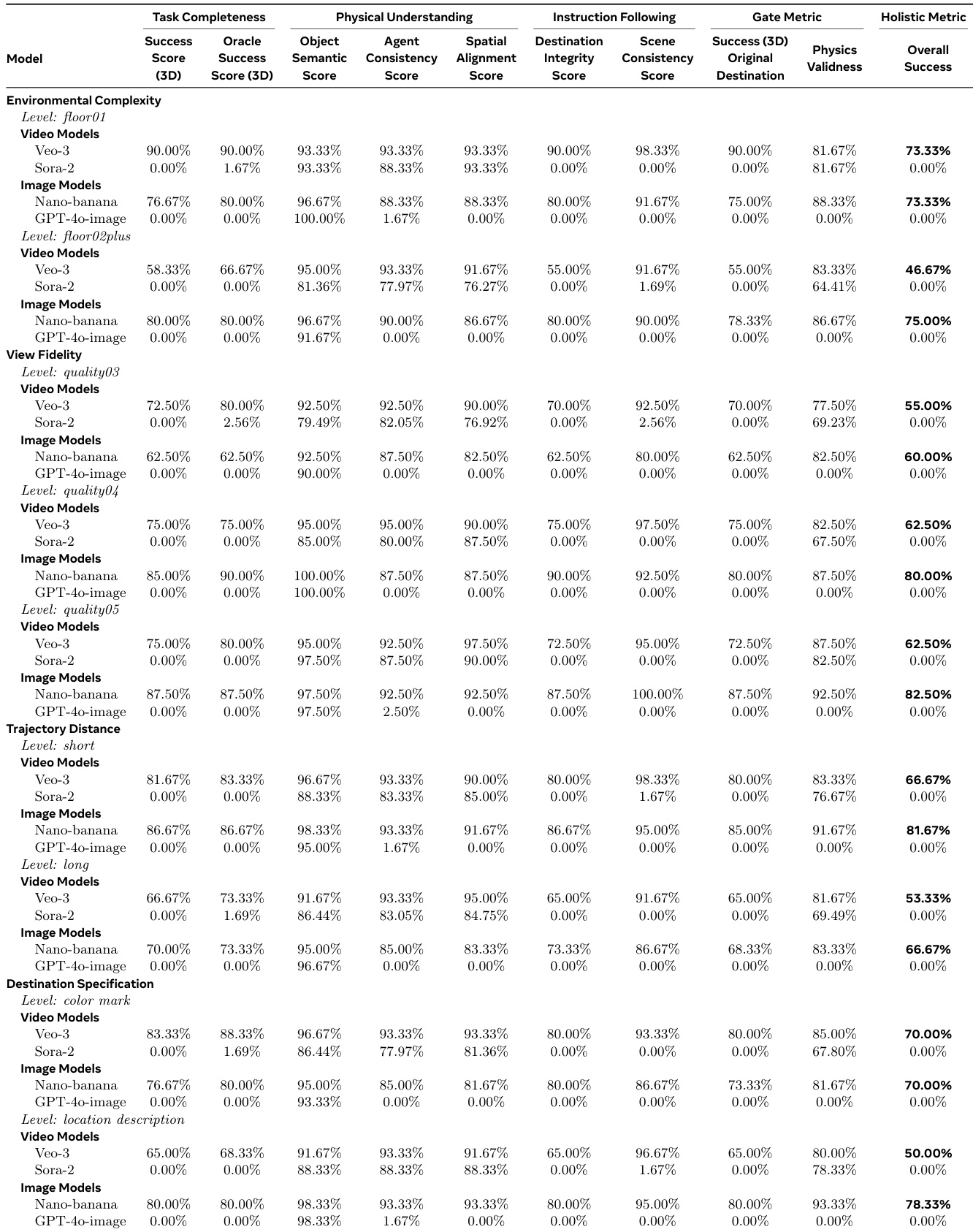
- For Embodied Navigation, Nano-banana achieved 79.2% holistic accuracy in 3D Real-World Navigation, while Veo-3 showed 73.33% AutoEval success in Panoramic View that dropped to 25.00% in human evaluation
- On Physical Commonsense, Sora-2 achieved 70.00% overall success, substantially outperforming Veo-3 (51.02%) and Wan-2.2 (24.00%), with results showing visual realism does not guarantee physical correctness
- Human evaluation consistently revealed critical gaps in automated metrics, exposing widespread "hallucination of competence" where models reached correct answers through invalid reasoning paths
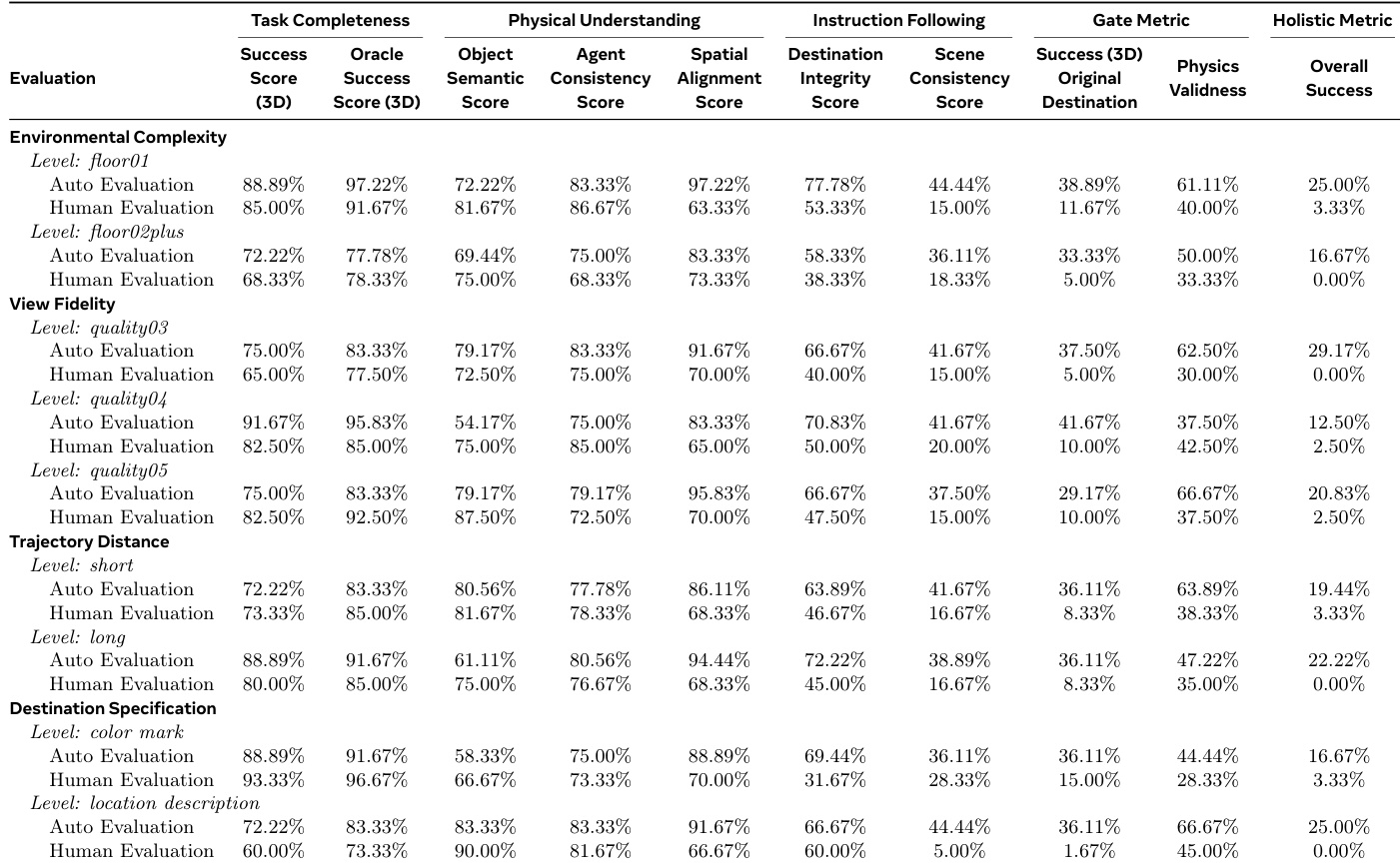
The authors use a multi-metric framework to evaluate video and image generative models on embodied navigation tasks, revealing that while video models like Veo-3 achieve high component scores in physical understanding and task completion, they consistently fail the strict holistic success metric that requires simultaneous satisfaction of all criteria. Image models, particularly Nano-banana, outperform video models in holistic accuracy across most conditions, especially under complex environments and textual destination specifications, indicating superior multimodal grounding and consistency. Results show a clear trade-off in video models between visual plausibility and strict adherence to physical and instructional constraints, with automated metrics often overestimating performance compared to human judgment.
The authors use the ARC-AGI benchmark to evaluate abstract visual reasoning, comparing video and image generative models across Match and Mismatch task types. Results show that image models, particularly Nano-banana Pro, significantly outperform video models in overall accuracy, with Nano-banana Pro achieving 33.33% on Match and 21.43% on Mismatch tasks, while video models like Veo-3 and Sora-2 score below 5% overall. This performance gap highlights that current video models struggle with maintaining structural and color consistency required for abstract pattern completion, even when they achieve moderate pattern recognition or grid integrity.
The authors use human and automated evaluation to assess Veo-3’s performance on 3D navigation tasks, revealing a significant gap between perceived and actual success. While automated metrics report moderate holistic scores (up to 25.00%), human evaluators consistently rate overall success near zero, exposing frequent physics violations and scene instability that automated systems overlook. This discrepancy highlights that current video models prioritize visual plausibility over physical and logical consistency, especially under complex or long-horizon conditions.
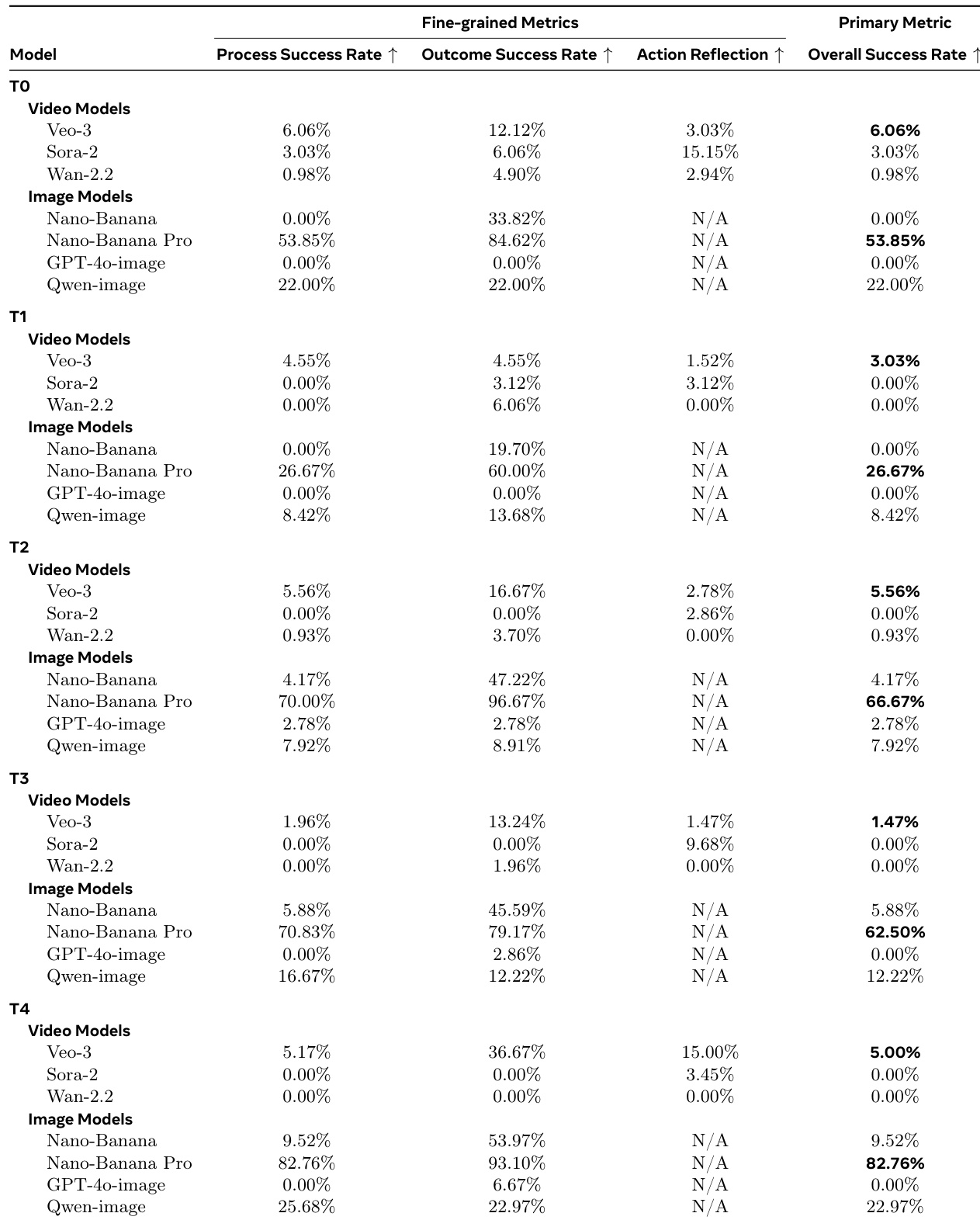
The authors use a multi-task math reasoning benchmark to evaluate video and image generative models, revealing a consistent performance gap where image models significantly outperform video models on overall success. Results show that video models like Veo-3 frequently achieve correct final answers (high Outcome Success Rate) despite flawed intermediate reasoning (low Process Success Rate), indicating they rely on pattern matching rather than causal deduction. Image models, particularly Nano-Banana Pro, maintain near-perfect alignment between process and outcome, demonstrating robust, step-by-step logical reasoning across all difficulty levels.
The authors use a strict overall metric requiring zero clue changes, zero constraint violations, and 100% completion accuracy to evaluate Sudoku-solving performance. Results show image models like Nano-banana Pro consistently outperform video models across all grid sizes and difficulty levels, with video models exhibiting high action reflection but frequent clue changes and constraint violations that prevent holistic success. Human evaluation further confirms that video models achieve near-zero overall success, revealing a fundamental gap between their step-by-step visual edits and actual logical correctness.